Introduction
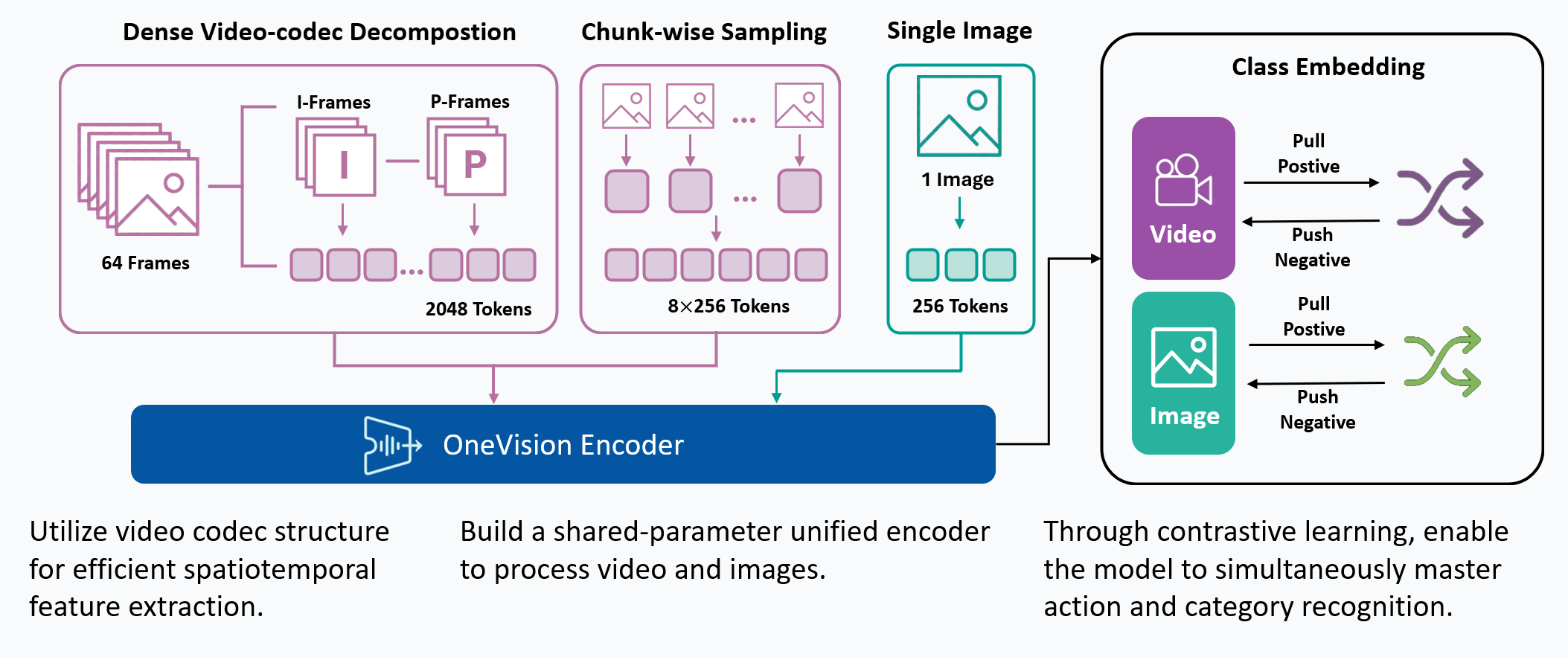
Hypothesis. Artificial general intelligence is, at its core, a compression problem. Effective compression demands resonance: deep learning scales best when its architecture aligns with the fundamental structure of the data. These are the fundamental principles. Yet, modern vision architectures have strayed from these truths: visual signals are highly redundant, while discriminative information, the surprise, is sparse. Current models process dense pixel grids uniformly, wasting vast compute on static background rather than focusing on the predictive residuals that define motion and meaning. We argue that to solve visual understanding, we must align our architectures with the information-theoretic principles of video, i.e., Codecs.
Method. OneVision-Encoder encodes video by compressing predictive visual structure into semantic meaning. By adopting Codec Patchification, OneVision-Encoder abandons uniform computation to focus exclusively on the 3.1%-25% of regions rich in signal entropy. To unify spatial and temporal reasoning under irregular token layouts, OneVision-Encoder employs a shared 3D RoPE and is trained with a large-scale cluster discrimination objective over more than one million semantic concepts, jointly capturing object permanence and motion dynamics.
Evidence. The results validate our core hypothesis: efficiency and accuracy are not a trade-off; they are positively correlated. By resolving the dichotomy between dense grids and sparse semantics, OneVision-Encoder redefines the performance frontier. When integrated into large multimodal models, it consistently outperforms strong vision backbones such as Qwen3-ViT and SigLIP2 across 16 image, video, and document understanding benchmarks, despite using substantially fewer visual tokens and pretraining data. Notably, on video understanding tasks, OneVision-Encoder achieves an average improvement of 4.1% over Qwen3-ViT. Under attentive probing, it achieves state-of-the-art representation quality, with 17.1% and 8.1% Top-1 accuracy improvements over SigLIP2 and DINOv3, respectively, on Diving-48 under identical patch budgets. These results demonstrate that codec-aligned, patch-level sparsity is not an optimization trick, but a foundational principle for next-generation visual generalists, positioning OneVision-Encoder as a scalable engine for universal multimodal intelligence.