OpenMMReasoner: Pushing the Frontiers for Multimodal Reasoning with an Open and General Recipe
Overview
Our contributions are threefold:
(1) Comprehensive Data Curation Insights.
We present the first systematic study on curating high-quality SFT and RL data for multimodal reasoning, supported by extensive and rigorous experiments across diverse modalities and reasoning types. We found that scaling data diversity is a critical factor for curating high-quality datasets. While diversity in data sources is important, diversity in answers represents an additional essential axis for improvement.
(2) A Strong SFT Recipe for Reasoning.
We present a robust and reproducible SFT recipe that effectively equips LMMs with strong reasoning capabilities. Our approach incorporates step-by-step validation and offers practical insights for scaling a high-quality data pipeline focused on reasoning. By carefully selecting an appropriate teacher model (Qwen3-VL-235B-Instruct) for rejection sampling with ×8 answer diversification, and incorporating cross-domain data sources (MMR1 for image-based math and MiroMind-M1 for text-based math), we construct an 874k-sample cold-start dataset that exhibits both high diversity and quality, forming a solid reasoning foundation for subsequent RL.
(3) An Advanced RL Recipe for Reasoning Enhancement.
We conduct a comprehensive comparative analysis of multiple RL strategies, including GSPO, GRPO, and DAPO, to evaluate their stability, efficiency, and scaling behavior. By selecting GSPO as the most suitable algorithm with a composite reward function (R = (1 - 0.1)·R_acc + 0.1·R_fmt) and ×16 rollout configuration, we establish a robust 74k-sample RL pipeline that further sharpens and stabilizes reasoning abilities, delivering both high stability and superior performance.

Performance Comparison with State-of-the-Art Large Multimodal Reasoning Models across Various Benchmarks. Our proposed OpenMMReasoner consistently outperforms competing methods, highlighting its effectiveness in complex reasoning tasks.
OpenMMReasoner-Data
OpenMMReasoner-Data presents two training recipes covering both the SFT and RL phases. The pipeline begins by collecting diverse data sources and selecting teacher models to generate new answer traces. During the RL phase, we explore different algorithm choices and filtering strategies, leading to our final optimized recipe.
SFT Data Curation Pipeline
The SFT dataset is constructed through three stages:
-
Data Sourcing and Formatting: We begin with approximately 103k raw question–answer pairs collected from public datasets including LLaVA-CoT, OpenVLThinker, and We-Math2.0. Data sourced from different benchmarks follow inconsistent answer styles and reasoning formats, so we standardize all samples to a unified reasoning format, normalizing textual structure and ensuring consistent step-wise outputs.
-
Data Distillation and Scaling: After selecting Qwen3-VL-235B-Instruct as the teacher model, we enrich each question with multiple verified reasoning traces. We evaluate four scaling factors (×1, ×2, ×4, ×8) and adopt the ×8 configuration, which increases the dataset to roughly 583k verified general-reasoning samples. Only samples whose final answers pass a rule-based validator and an LLM-as-judge check are retained.
-
Domain Mixing: To further enhance reasoning generalization, we incorporate MMR1 for image-based mathematical reasoning and MiroMind-M1 for text-based mathematical reasoning. Combining the general SFT data with these additional mathematical datasets yields our final 874k mixed SFT dataset.
RL Data Curation Pipeline
The RL dataset comprises approximately 74k samples curated through:
-
Dataset Sourcing: We collect diverse data samples from MMEureka, ViRL, TQA, We-Math, PuzzleVQA, AlgoPuzzleVQA, and ThinkLiteVL, covering domains such as science, mathematics, charts, and puzzles.
-
Dataset Cleaning: We extract and verify final answers from each dataset, then deduplicate by computing both image and text similarities to remove redundant questions. The cleaned datasets are merged to form the final RL dataset.
Training Framework
For SFT training, we adopt online packing and the Liger-Kernel to accelerate training efficiency, using LMMs-Engine as the training framework and LMMs-Eval for standardized evaluation. We use Qwen2.5-VL-7B-Instruct as our initial checkpoint to start. For RL training, we utilize verl and vllm to accelerate the training process with a global batch size of 128.

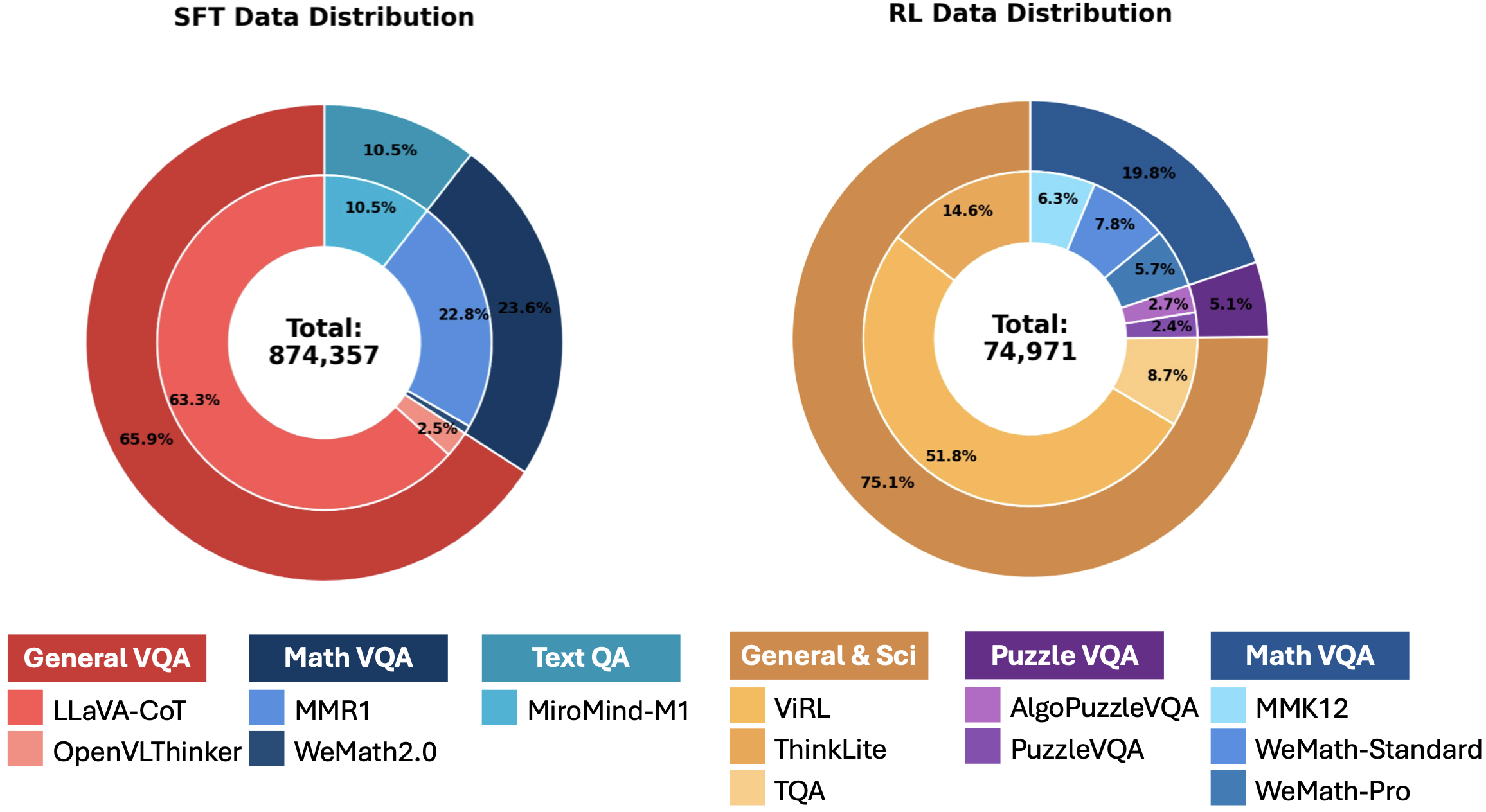
Experimental Results on Visual Reasoning Benchmarks
We evaluate our approach on a suite of public visual reasoning benchmarks including MathVista, MathVision, MathVerse, DynaMath, WeMath, LogicVista, MMMU, MMMU-Pro, and CharXiv. Extensive evaluations demonstrate that our training recipe not only surpasses strong baselines but also highlights the critical role of data quality and training design in shaping multimodal reasoning performance.
SFT Results
Our SFT model (OMR-7B-ColdStart) with 874k samples achieves state-of-the-art results among SFT methods across most benchmarks, significantly outperforming other open-source models with much larger training datasets:
- MathVista-testmini: 74.8% (vs. 69.6% for LLaVA-OneVision-1.5-8B with 105M samples)
- MathVision-test: 36.6% (vs. 28.6% for InternVL3-8B)
- MathVerse-testmini: 33.9% (vs. 25.6% for Qwen2.5-VL-7B baseline)
- DynaMath-worst: 57.7% (vs. 46.3% for LLaVA-OneVision-1.5-8B)
- WeMath: 29.3% (vs. 23.0% for InternVL3-8B)
- LogicVista-test: 67.2% (vs. 53.1% for Qwen2.5-VL-7B baseline)
- MMMU-val: 46.2% (vs. 47.9% for Qwen2.5-VL-7B baseline)
RL Results
After RL training with 74k samples using GSPO, our model (OMR-7B) achieves further improvements and state-of-the-art results among open-source methods:
- MathVista-testmini: 79.5% (+4.7% from SFT)
- MathVision-test: 43.6% (+7.0% from SFT)
- MathVerse-testmini: 38.8% (+4.9% from SFT)
- DynaMath-worst: 63.8% (+6.1% from SFT)
- WeMath: 34.9% (+5.6% from SFT)
- LogicVista-test: 79.0% (+11.8% from SFT)
- MMMU-val: 50.0% (+3.8% from SFT)
- MMMU-Pro-standard: 57.8% (+8.1% from SFT)
Notably, our method achieves an 11.6% improvement over the Qwen2.5-VL-7B-Instruct baseline across nine multimodal reasoning benchmarks, demonstrating superior data efficiency (874k SFT + 74k RL) compared to methods requiring millions of training samples. Additionally, our model maintains higher reasoning efficiency compared to OVR, achieving better accuracy while using significantly less token budget.
Analysis and Insights for SFT
Our Analysis and Insights for SFT are as follows:
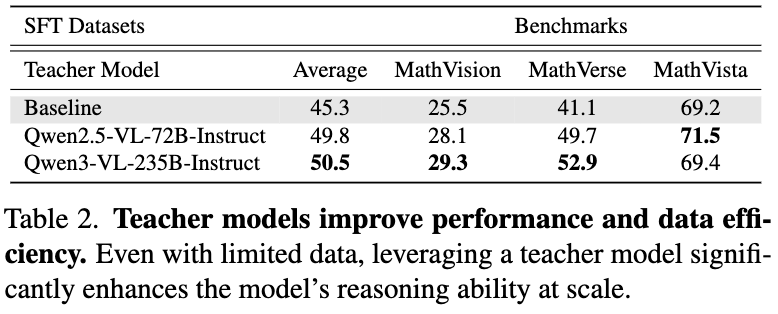
(1) Answer diversity enhances reasoning.
Increasing the diversity of generated answers consistently improves the model's overall reasoning performance, even when using the same question sources, suggesting that exposure to varied solutions strengthens understanding. We evaluate four scaling factors—×1, ×2, ×4, and ×8—observe consistent improvements as the number of verified answers increases. Quantitatively, increasing the number of verified answers per question from ×1 to ×8 raises the average benchmark performance from 50.5 to 55.2, demonstrating that answer diversity is a crucial factor for data quality and model generalization.
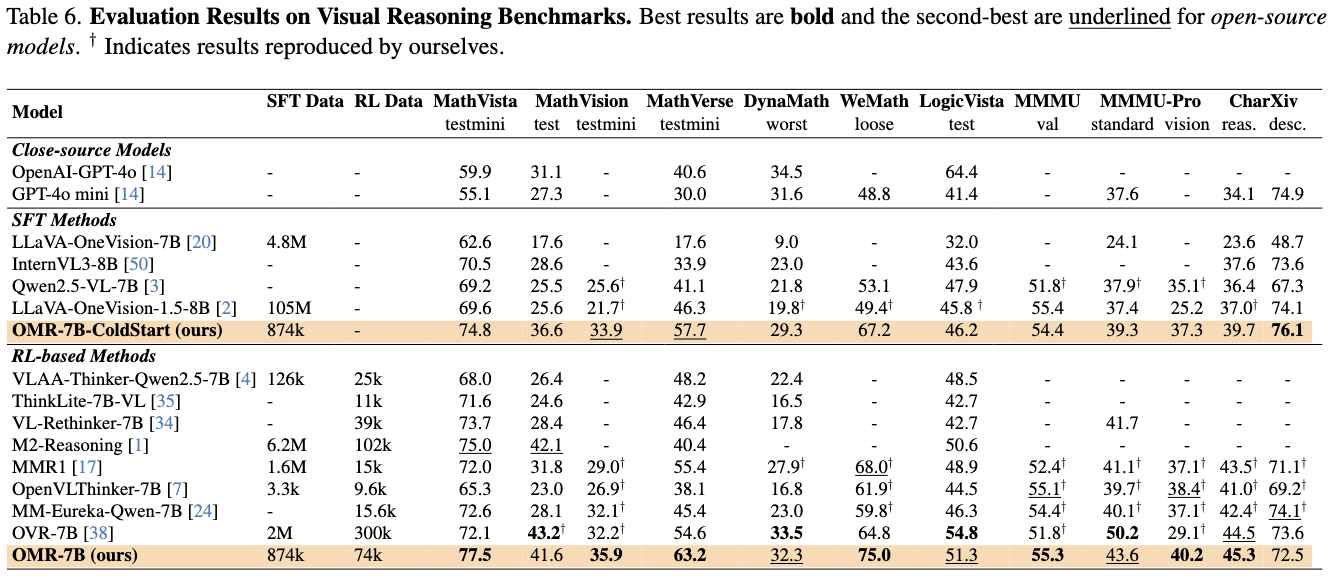
(2) Teacher model selection is crucial.
Distilling from a strong teacher model substantially boosts the model's reasoning ability while maintaining high data efficiency. Careful selection for teacher model directly affects the quality of the distilled dataset and the final model performance. We compare answer traces distilled from multiple candidates, applying both format validation and answer verification using a rule-based validator and an LLM-as-judge check. Both stronger teacher models provide an average gain of at least 4.5 points across all benchmarks, with Qwen3-VL-235B-Instruct achieving the highest performance and selected as the teacher for distillation.
(3) Over-filtering reduces diversity and performance.
The best results are achieved without excessive filtering, indicating that maintaining greater answer diversity encourages more robust reasoning abilities. We evaluate two common filtering strategies—difficulty-based filtering (approximated from previous sampling accuracy) and length-based filtering (token count to remove extremely short examples). Both filtering strategies reduce performance, which we attribute to the loss of answer diversity, leading us to adopt a no-filtering policy.
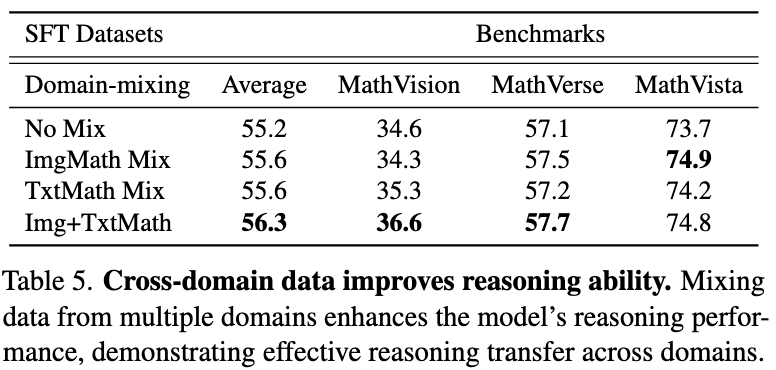
(4) Cross-domain knowledge improves generalization.
Incorporating diverse data from multiple domains consistently enhances the model's overall reasoning capabilities across tasks. While the 583k distilled dataset provides strong multimodal reasoning, its coverage of mathematical reasoning remains limited. We therefore integrate MMR1 for image-based mathematical reasoning and MiroMind-M1 for text-based mathematical reasoning. Adding both types of mathematical supervision consistently improves performance across multimodal and reasoning benchmarks.
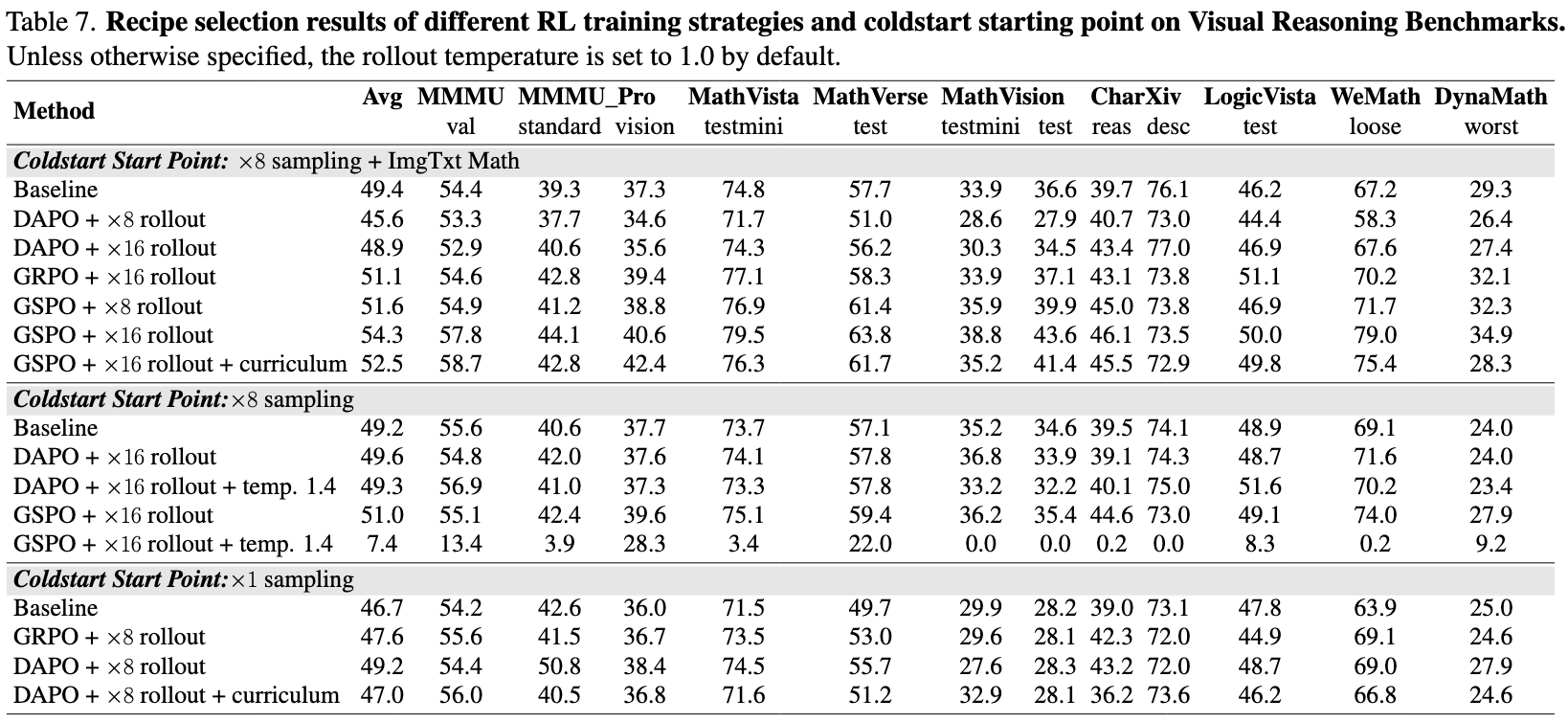
Analysis and Insights for RL
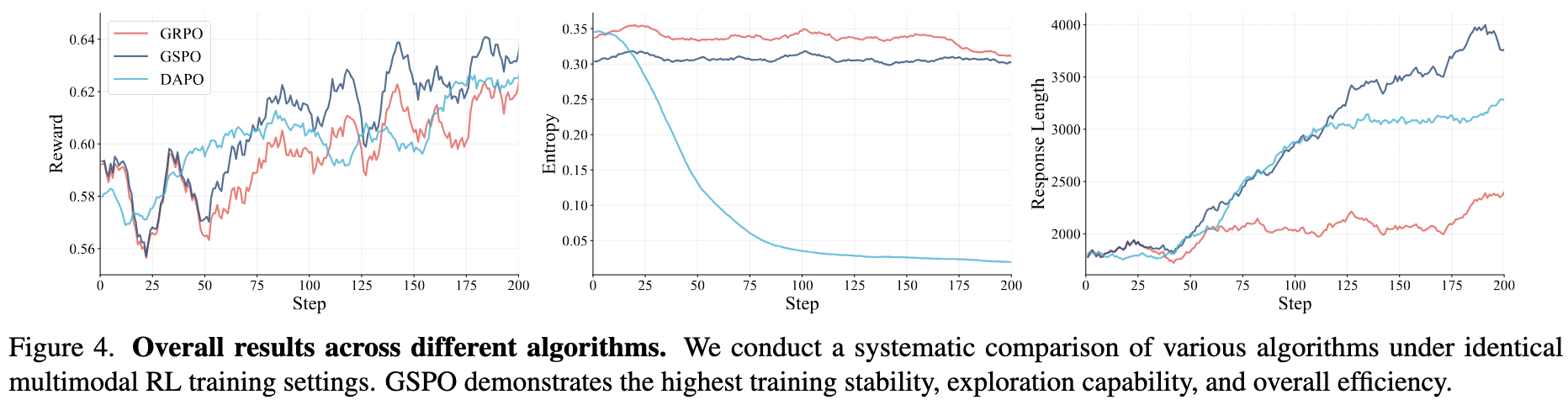
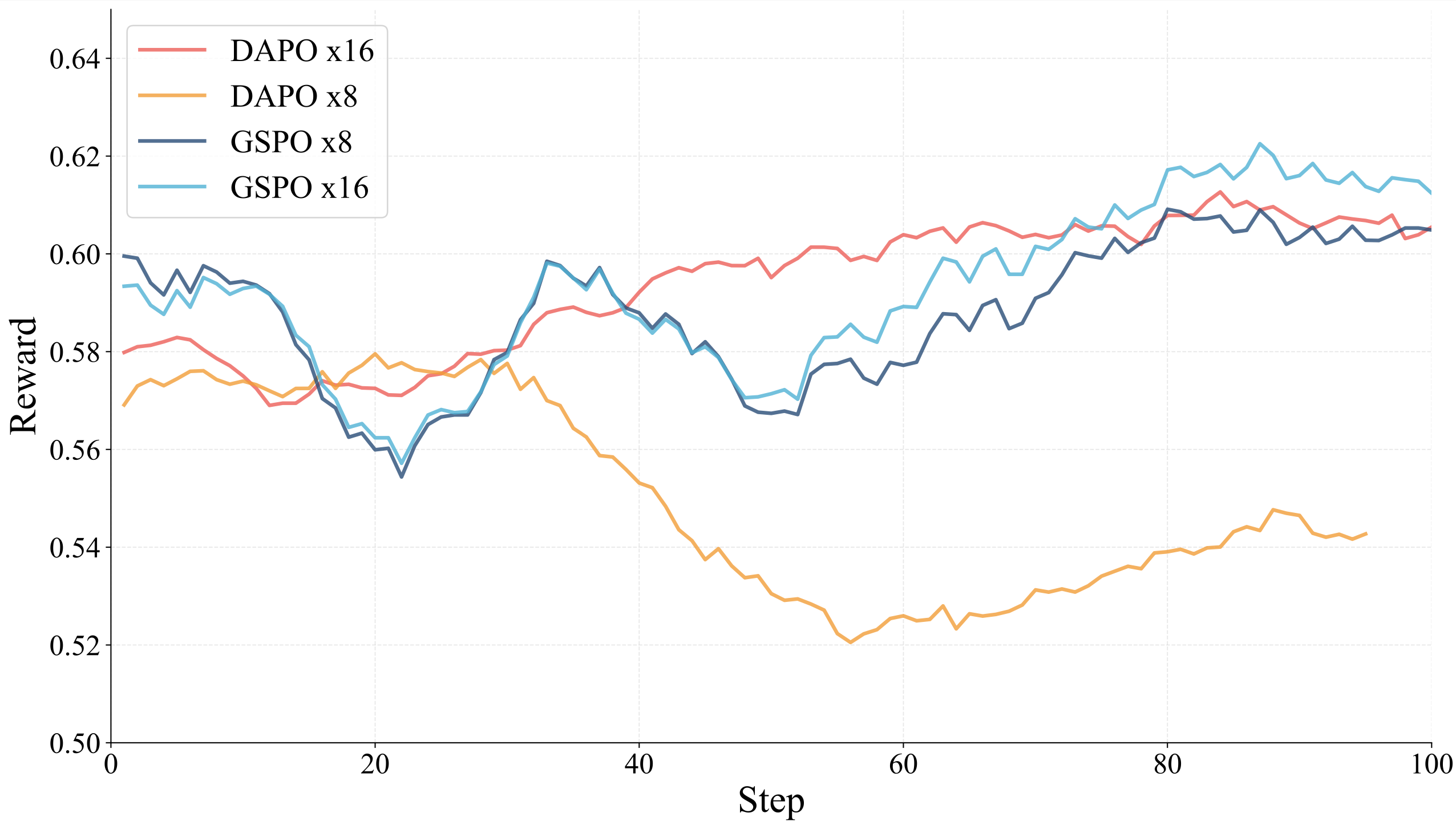
We conduct a comprehensive comparative analysis of multiple RL strategies, including GSPO, GRPO, and DAPO, to evaluate their stability, efficiency, and scaling behavior. GSPO demonstrates superior stability and faster convergence compared to alternative methods in multimodal RL training, effectively balancing exploration and stability. GRPO shows moderate stability but converges more slowly, while DAPO exhibits early entropy collapse and slower progress due to larger rollout requirements.
RL Algorithm Details
-
GRPO removes the need for a critic network and Generalized Advantage Estimation (GAE), normalizes rewards within each rollout group to reduce variance, and incorporates likelihood-ratio clipping with a KL-divergence penalty to constrain the policy close to the initial SFT policy.
-
DAPO addresses limitations of GRPO including entropy collapse, training instability, and length bias caused by sample-level loss through a decoupled clipping mechanism and a dynamic sampling strategy.
-
GSPO tackles the token-level importance bias inherent in GRPO by introducing a sequence-level importance ratio for optimization and employs a smaller clipping threshold to enhance training stability.
Reward Function
We adopt a composite reward function that balances task accuracy and output formatting:
R = (1 - λ_fmt) · R_acc + λ_fmt · R_fmt
where R_acc measures correctness on the task objective, R_fmt captures answer format consistency, and λ_fmt ∈ [0,1] controls the trade-off. We use λ_fmt = 0.1 throughout our RL experiments.
Training Configuration
For RL training, we use verl and vllm to accelerate the training process with a global batch size of 128. During generation, we set the maximum number of new tokens to 28,696, cap the prompt length at 4,096 tokens (max length 32,792), and use a temperature of 1.0. The dataset comprises approximately 74k samples from diverse sources including MMEureka, ViRL, TQA, We-Math, PuzzleVQA, AlgoPuzzleVQA, and ThinkLiteVL.
Key Factors for Stable Training
We identify two factors that critically affect RL training stability:
- Rollout Temperature: Higher temperatures (e.g., 1.4) cause significant instability and occasional divergence, suggesting excessive exploration amplifies policy gradient variance.
- Rollout Count: The ×16 configuration consistently yields higher rewards and smoother dynamics compared to ×8, which is especially pronounced for DAPO where the ×8 setting exhibits severe late-stage instability and training collapse.
Our Analysis and Insights for RL are as follows:
(1) GSPO outperforms other algorithms.
GSPO demonstrates superior stability and faster convergence compared to alternative methods in multimodal RL training, achieving an effective balance between exploration and stability.
(2) Token efficiency is crucial.
While increasing reasoning steps at test time can improve performance, excessive tokens reduce efficiency. Our results show that a smaller reasoning budget can achieve comparable or even better accuracy. We employ an overlength penalty strategy to mitigate overthinking behavior and achieve a balanced trade-off between reasoning depth and efficiency.
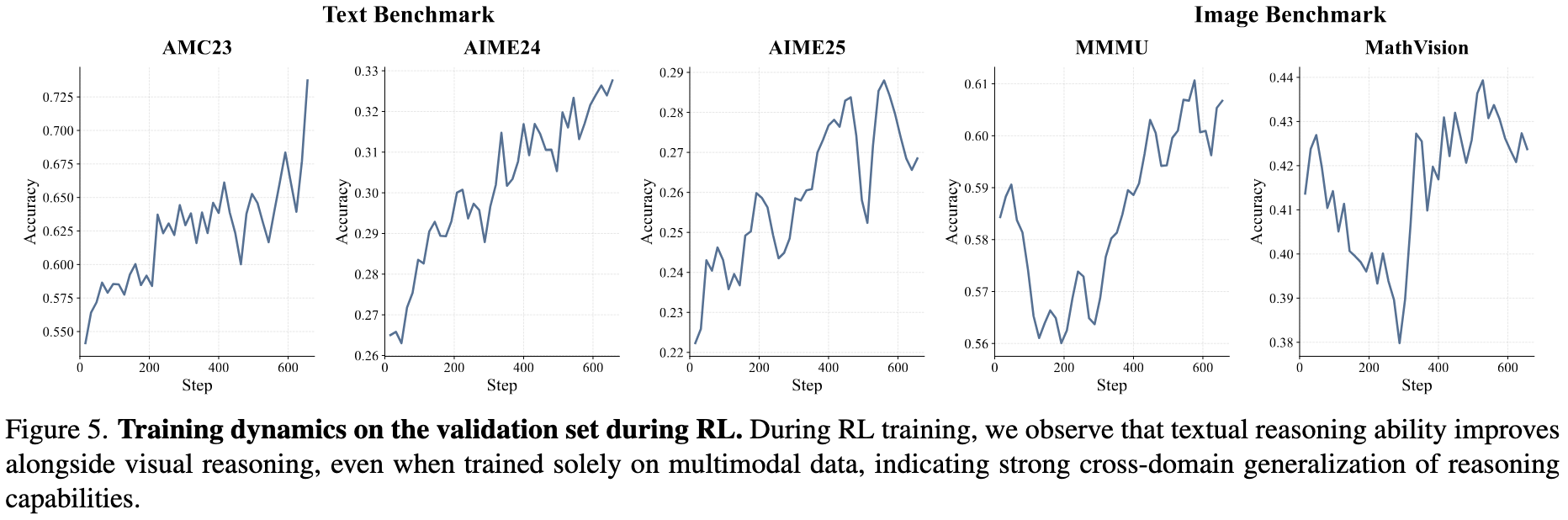
(3) Reasoning ability transfers across domains.
Gains in reasoning during training consistently translate into stronger performance across multiple domains. We observe textual reasoning behaviors emerging alongside strengthened multimodal reasoning, with validation performance on AIME24, AIME25, and AMC23 steadily increasing throughout training, reflecting continuous gains in text-based reasoning capabilities.
Open-Source Resources
We open-source OpenMMReasoner to facilitate future development of multimodal reasoning in the community