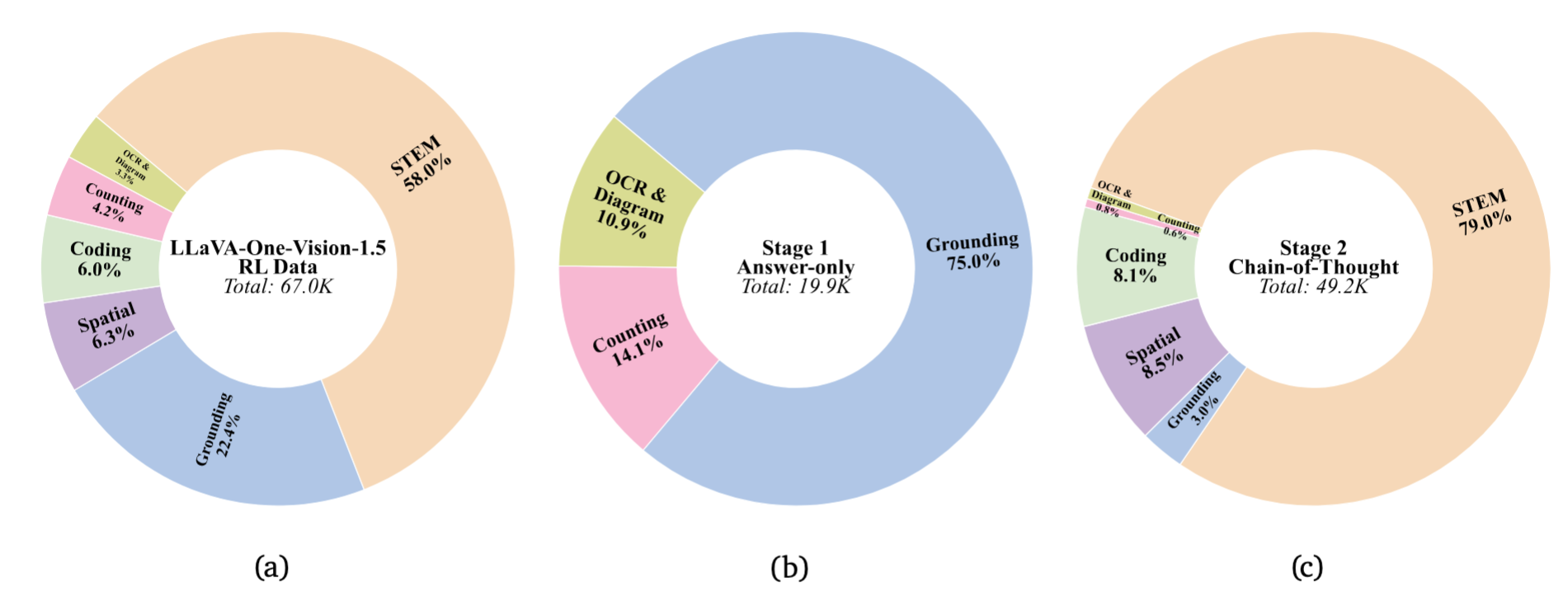
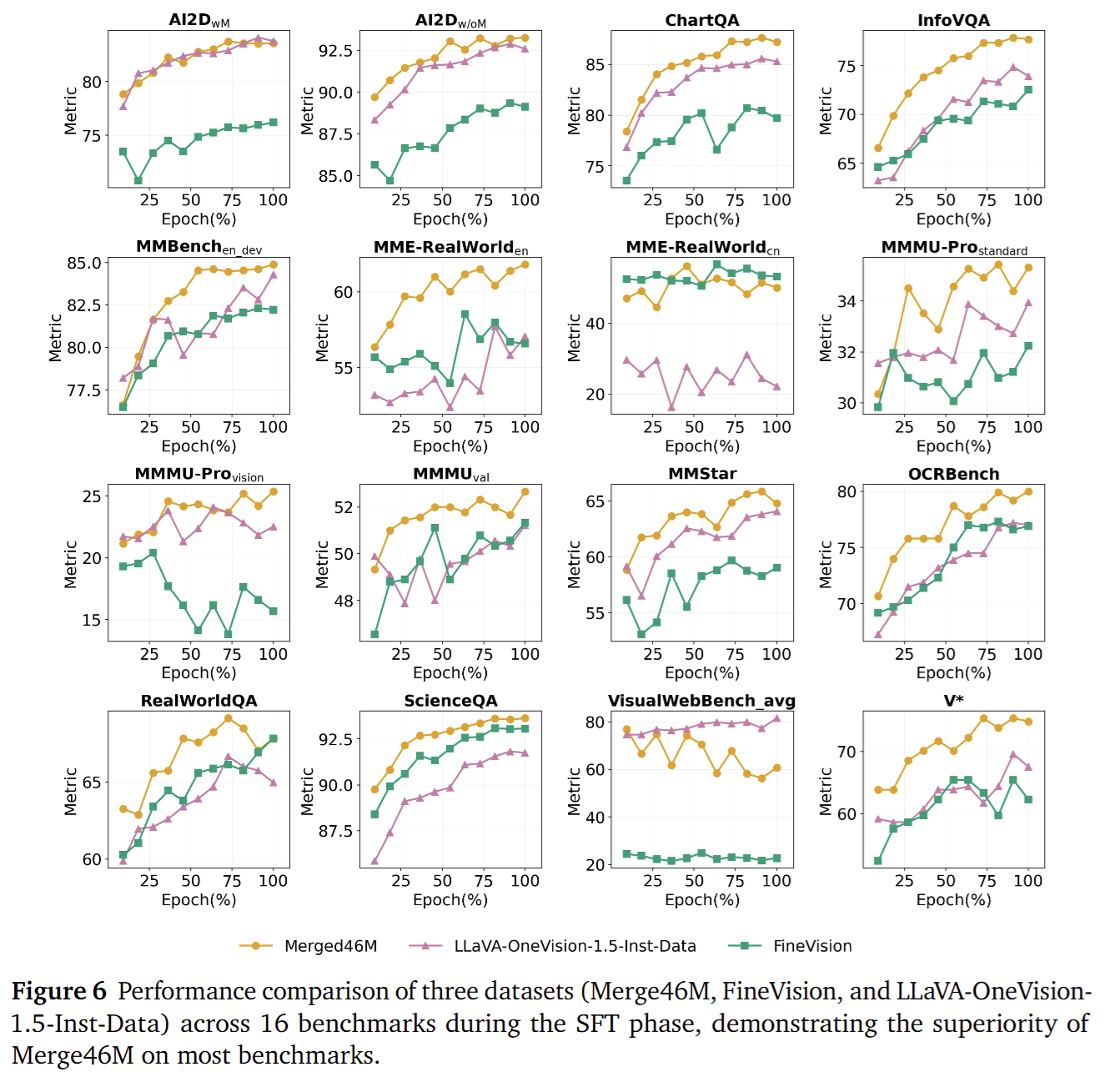
LLaVA-OneVision-1.5-RL presents an RL post-training stage utilizing 67K curated examples with discrepancy-based selection to generate explicit chain-of-thought reasoning, achieving significant performance gains on STEM, coding, and reasoning benchmarks while maintaining visual understanding capabilities.
Our contributions are threefold:
(1) Discrepancy-Driven Data Curation.
We identify tasks where model performance gap exists between Pass@N and Pass@1 metrics, targeting “latent capability” rather than knowledge injection.
(2) Rule-Based Reward System.
We employ domain-specific verification rules rather than learned preference models, enabling precise feedback across STEM, grounding, spatial reasoning, counting, coding, OCR, and diagram tasks.
(3) Two-Stage Curriculum Training.
We design a training curriculum that first stabilizes concise task performance with answer-only RL, then unlocks deeper reasoning through chain-of-thought RL.
Distribution of task categories in the RL training data (67K total instances)
RL Data Strategy
Discrepancy-Driven Selection
We identify tasks where model performance gap exists between Pass@N and Pass@1 metrics. This approach targets “latent capability” rather than knowledge injection, ensuring the model learns to better utilize its existing knowledge.
Reward-Based Sampling
Multiple candidate responses are filtered by average reward scores to exclude trivial and unsolvable cases, focusing on medium-difficulty instances that provide optimal learning signals.
Reward System Architecture
We employ a rule-based paradigm with domain-specific verification rules rather than learned preference models:
Category
Source
Reward Design
STEM
ViRL39K
Choice accuracy & math expression equivalence
Grounding
Ref-L4, VigoRL-SA
IoU between predicted/reference boxes; choice accuracy
Spatial
VigoRL-SAT
Choice accuracy
Counting
PixmoCount
Numeric token equivalence
Coding
WebCode2M, UniSVG
Token/tag overlap; SVG rendering similarity [0,1]
OCR
InfoVQA
Text similarity
Diagram
AI2D
Choice accuracy
Two-Stage Training Procedure
Training uses Group Relative Policy Optimization (GRPO) within the AReaL asynchronous framework:
Stage 1: Answer-only RL
Normal split training with instruction “Put ONLY your final answer within <answer></answer>.” This stage stabilizes concise task performance.
Stage 2: Chain-of-Thought RL
Long-reasoning data with instruction “Think and solve… within <think></think>…” This stage unlocks deeper reasoning capabilities. A small proportion of normal-set examples are interspersed to prevent forgetting perception skills.
Performance Results
Core Capability Enhancement
General VQA Benchmarks (Average +1.0):
Benchmark
Base
+RL
MMStar
67.7
68.2
MMBench (EN)
84.1
85.7
MMBench (CN)
81.0
84.2
MME-RealWorld (EN)
61.7
63.4
CV-Bench
80.7
82.9
RealWorldQA
68.1
68.4
Reasoning Tasks (Average +6.0):
Benchmark
Base
+RL
Δ
MathVista Mini
69.6
72.3
+2.7
WeMath
61.5
69.4
+7.9
MathVision
25.6
34.4
+8.8
MMMU Validation
55.4
58.8
+3.4
MMMU-Pro
25.2
35.7
+10.5
OCR & Chart (Average +0.0):
Benchmark
Base
+RL
ChartQA
86.5
87.4
DocVQA
95.0
91.9
InfoVQA
78.4
76.6
Extended Capability Analysis
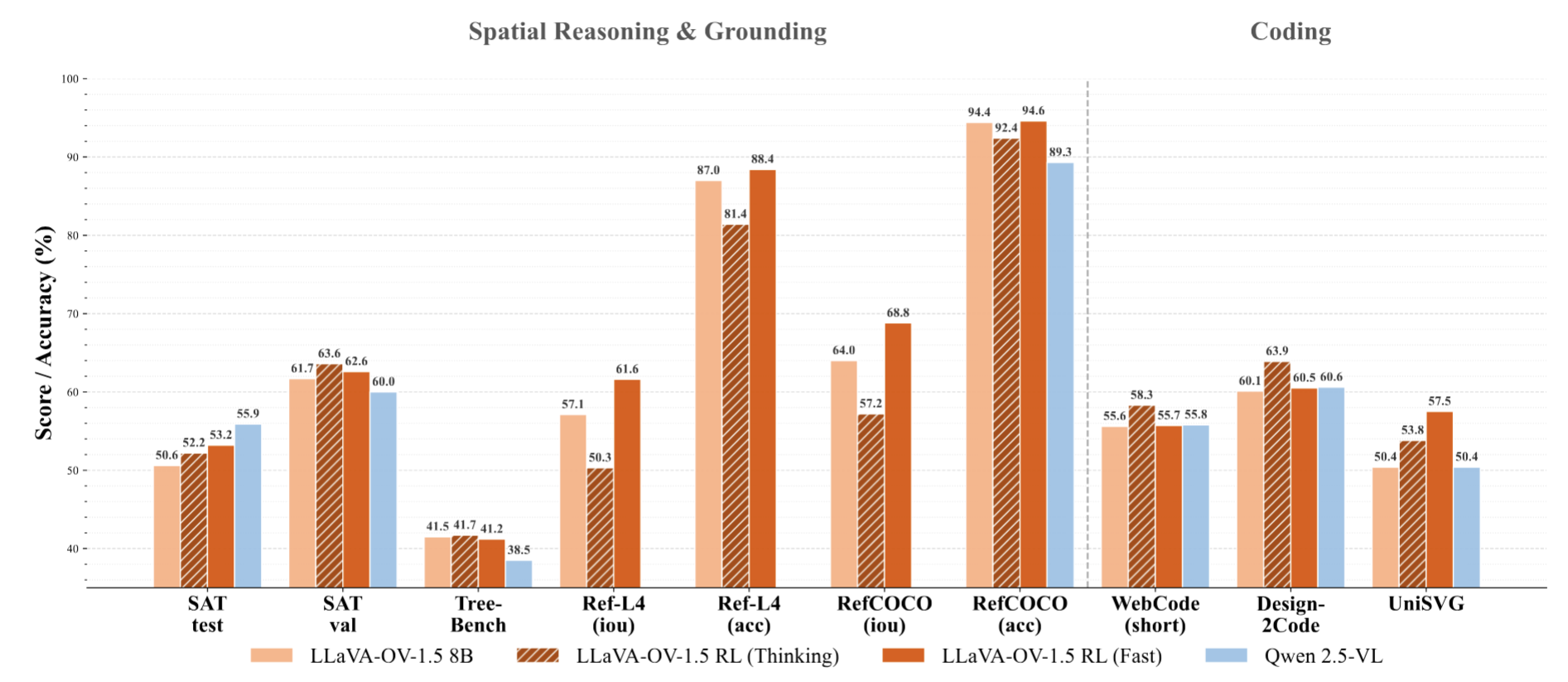
Performance comparison of LLaVA-OV-1.5 and corresponding RL version on Spatial Reasoning & Grounding and Coding tasks
Spatial & Grounding: RL “fast mode” significantly enhances fine-grained perception on SAT and Ref-L4 benchmarks.
Coding: “Thinking” mode achieves highest scores on Design2Code and UniSVG, demonstrating chain-of-thought benefits for structural code generation.
Development Roadmap
This release represents Stage 3 in a multi-phase project:
Stage
Focus
Data Scale
Stage 1 & 1.5
Pre-training & Mid-training
85M multimodal samples
Stage 2
Visual instruction tuning (SFT)
22M instruction-following samples
Stage 3 (Current)
RL post-training with GRPO
67K curated samples
Acknowledgements
We thank the following projects and frameworks:
AReaL: Lightning-Fast RL for LLM Reasoning and Agents
sglang: Fast serving framework for LLMs and vision language models
High performance, low cost, and strong reproducibility!
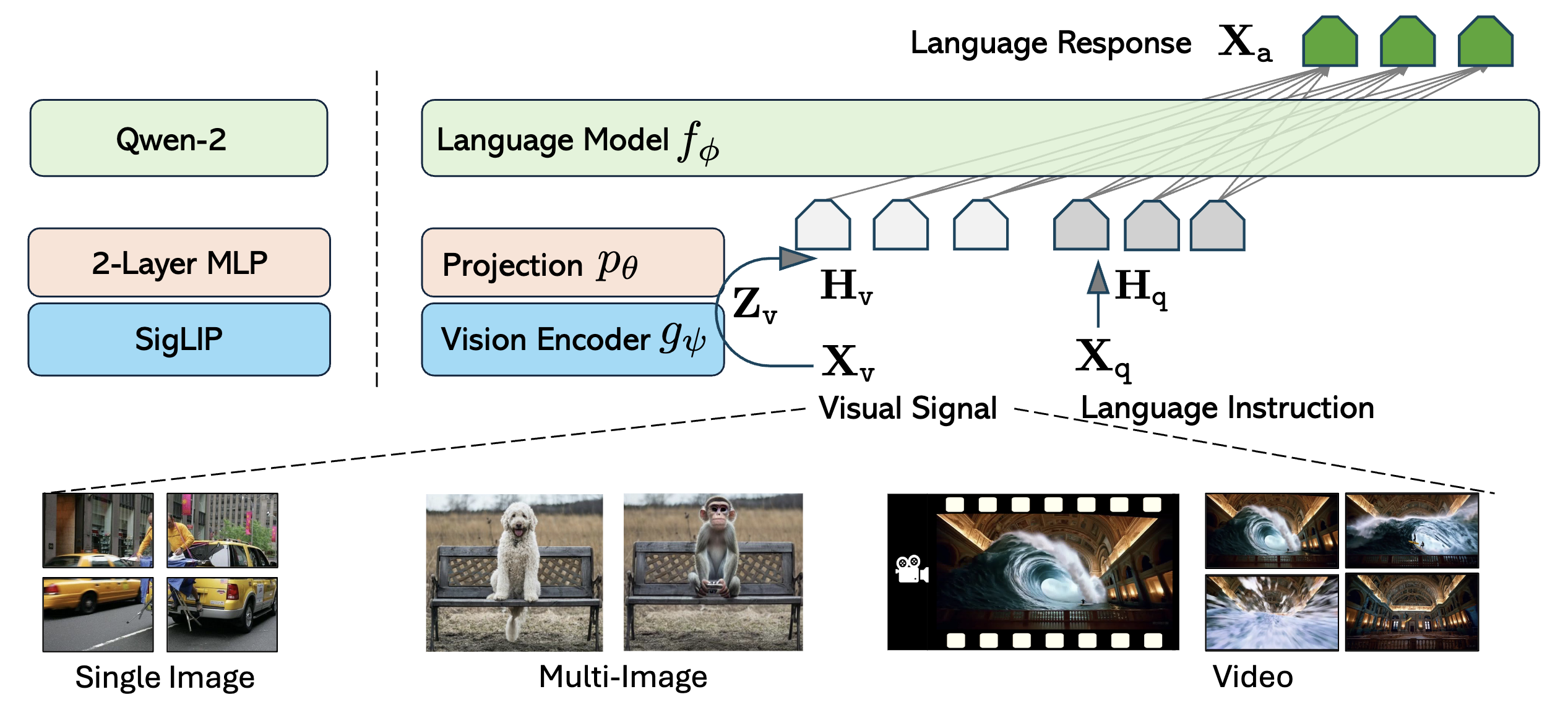
LLaVA, proposed in 2023, efficiently connects open-source vision encoders with large language models through low-cost alignment, bringing “see—understand—converse” multimodal capabilities to the open ecosystem. It significantly narrows the gap with top-tier closed models and marks an important milestone in open-source multimodal paradigms.
Starting with a low-cost alignment that bridges “vision encoder + large language model,” LLaVA laid the groundwork; LLaVA-1.5 strengthened comprehension with larger, cleaner data and high-resolution inputs; LLaVA-NeXT expanded into OCR, mathematical reasoning, and broader, multi-scenario tasks. It then branched into LLaVA-NeXT-Video for temporal video understanding and multi-frame reasoning, and LLaVA-NeXT-Interleave to support interleaved multi-image–text inputs and cross-image joint reasoning. Ultimately, the line converged in LLaVA-OneVision, which provides a unified interface covering images, documents, charts, multi-image, and video, balancing quality and efficiency.
Although interfaces and architectures for multimodal alignment are trending toward convergence, a truly “reproducible” open-source path still differs from releases that “open weights only.” Qwen2.5-VL and InternVL3.5 set strong baselines in OCR, document understanding, mathematical and cross-image reasoning; however, full data inventories, cleaning and mixing ratios, as well as alignment/sampling and training schedules are often only partially disclosed, making end-to-end reproduction difficult. Molmo, with a cleaner data pipeline and meticulous design, approaches strong closed-source baselines across multiple evaluations and human preference settings; Open-Qwen2VL shows that under a more efficient paradigm, strong comparative performance is achievable even when raw multimodal tokens account for a relatively small proportion. The primary gap today lies in the “reproducibility of recipes and engineering details,” rather than any single choice of model architecture.
LMMs-Lab, focused on the goals of high performance, low cost, and strong reproducibility, releases on top of the LLaVA‑OneVision framework a fully open, concept-balanced 85M pretraining dataset (LLaVA‑OV‑1.5‑Mid‑Training‑85M) and a carefully curated 22M instruction dataset (LLaVA‑OV‑1.5‑Instruct‑22M). We retain a compact three-stage pipeline (Stage‑1 language–image alignment; Stage‑1.5 concept balancing and high-quality knowledge injection; Stage‑2 instruction tuning), combine offline parallel data packing (up to ~11× padding compression) with Megatron‑LM plus a distributed optimizer, and complete Stage‑1.5 pretraining of an 8B‑scale VL model on 128 A800 GPUs in about four days.
Building on this, we introduce LLaVA‑OneVision‑1.5, which inherits and extends the LLaVA series: it adds RICE‑ViT for native-resolution, region-level fine-grained semantic modeling; strengthens chart/document/structured-scene understanding; continues the compact three-stage paradigm to avoid a lengthy curriculum; and emphasizes “quality–coverage–balance” across the 85M pretraining and 22M instruction sets. Crucially, it delivers truly end-to-end transparent openness—covering data, training and packing toolchains, configuration scripts, logs, and reproducible evaluation commands with their build and execution details—to enable low-cost reproduction and verifiable extension by the community. Experiments show LLaVA‑OneVision achieves competitive or superior performance to Qwen2.5‑VL on multiple public multimodal benchmarks (see the technical report).
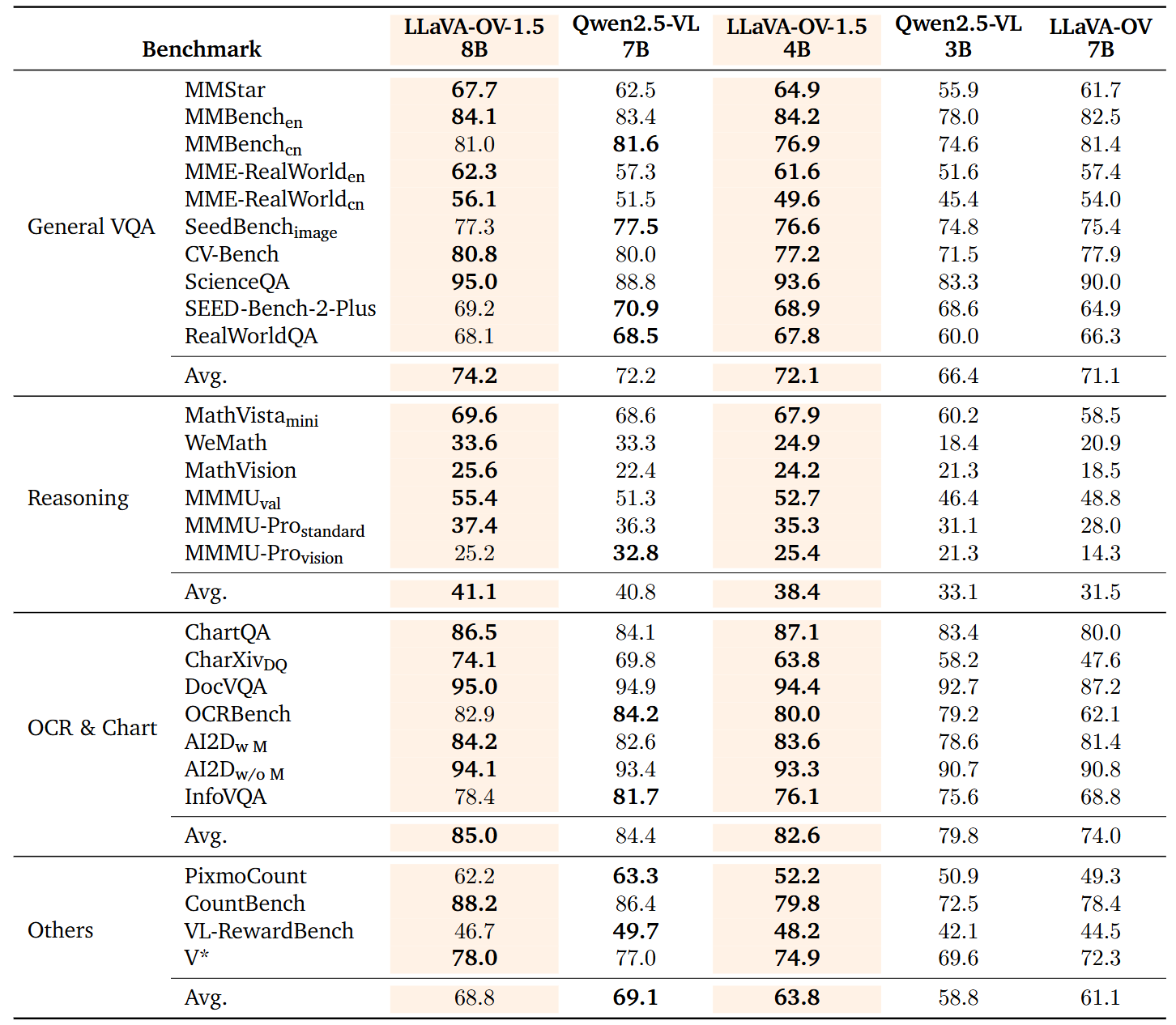
Pretraining Dataset (85M) and Concept Balancing
A general-purpose vision–language pretraining dataset (85M) and an instruction-tuning dataset (22M). The 85M pretraining corpus fuses eight heterogeneous sources—COYO-700M, Obelics, DataComp-1B, LAION-CN, ImageNet-21K, SAM-1B, MINT, and Zero250M—yielding roughly 20 million Chinese and 65 million English image–text pairs. To tackle long-tail concept sparsity and noise/missing issues in raw captions, we move beyond raw term frequencies and adopt a feature-driven “concept balancing” strategy: using a MetaCLIP encoder, we embed all images and a 500K-scale concept vocabulary into a shared vector space, retrieve the Top-K most similar concepts for each image, tally concept frequencies, and then apply inverse-frequency weighted resampling. This suppresses high-frequency background classes and boosts rare fine-grained entities, attributes, and scenes, substantially flattening the long-tail distribution. We then use a high-quality captioner to generate aligned bilingual (Chinese/English) augmented descriptions. Systematic experiments show that, under the same or lower token budget, scaling high-quality data combined with concept-balanced sampling delivers significant and reproducible gains in multimodal understanding, long-tail recognition, and instruction generalization.
Instruction Dataset (22M)
The 22M instruction dataset covers eight categories: Caption, Chart & Table, Code & Math, Domain-specific, General VQA, Grounding & Counting, OCR, and Science. Through multi-source aggregation, format standardization, instruction rewriting, bilingual conversion, template diversification (to reduce homogeneity), and safety filtering, we maintain balanced distributions across categories and difficulty levels. Moreover, augmenting our instruction data with the FineVision dataset yields further performance gains.
Method
1) Visual Encoder Pretraining
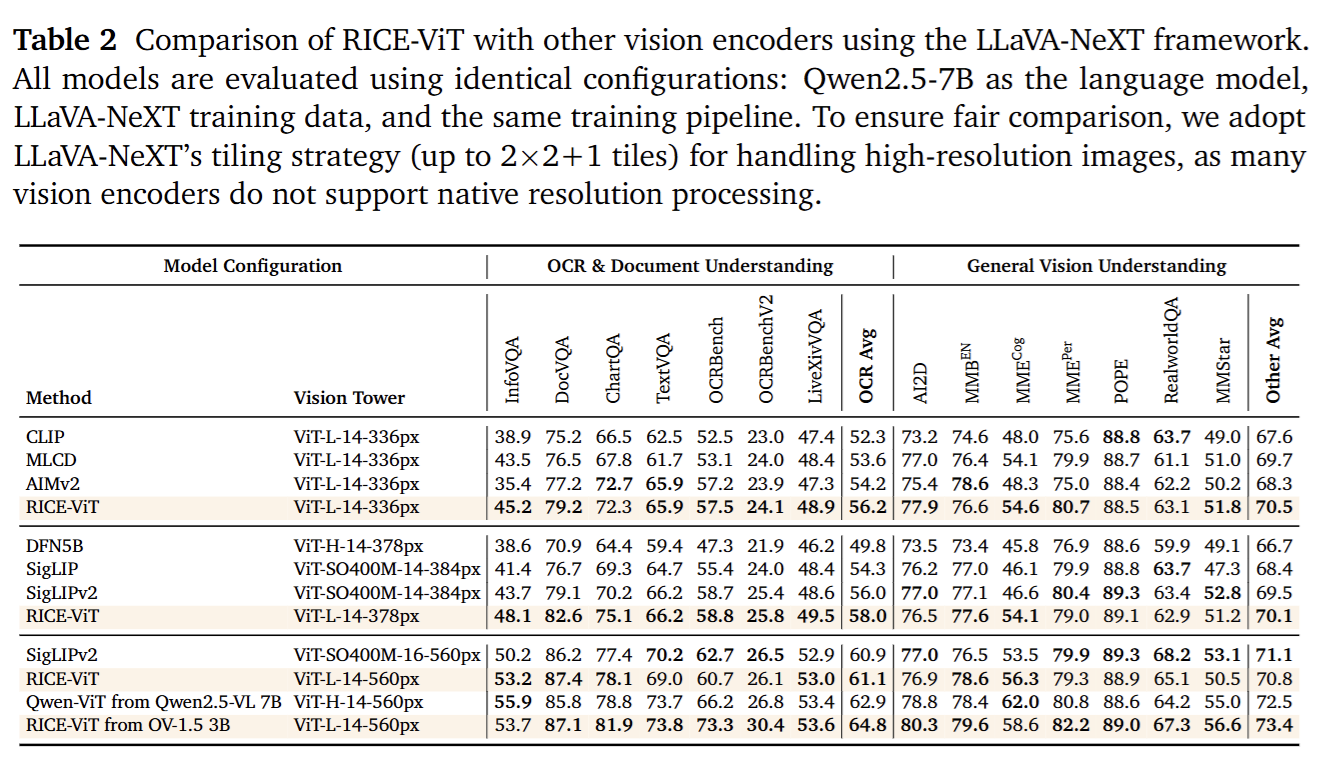
To raise the floor for OCR, tables/documents, region‑level understanding, and downstream instruction reasoning, LLaVA‑OneVision‑1.5 adopts our in‑house MVT v1.5 (RICE‑ViT) as the vision backbone.
Compared to CLIP/SigLIP‑style contrastive models that rely on global alignment only, RICE‑ViT addresses the structural bottleneck of representing an instance with a single global vector by introducing a unified Region Cluster Discrimination mechanism:
trained on 450M images and 2.4B candidate regions
explicitly models local entities/text blocks and their context via region‑cluster discrimination plus region‑aware attention
uses 2D rotary position encoding (2D RoPE) for native multi‑resolution support
Unlike SigLIP2, which relies on multiple specialized losses (SILC, TIPS, LocCa, etc.), we use a single clustering‑discrimination paradigm to simultaneously strengthen general semantics, OCR recognition, and localization, yielding a simpler, more maintainable training/inference pipeline.
During multimodal fusion, a lightweight projection followed by full‑parameter joint training seamlessly plugs this fine‑grained semantic foundation into the language model, reducing redundant adapters and improving cross‑task transfer efficiency.
2) Three‑Stage Learning Pipeline
Stage‑1: Language–image alignment
Train the visual projection layer on the LLaVA‑1.5 558K dataset to map visual encoder outputs into the LLM’s token embedding space, with controlled parameter updates for fast, stable convergence.
Stage‑1.5: Mid‑stage pretraining with high‑quality knowledge
Full‑parameter training on the concept‑balanced 85M pretraining set to inject broad visual semantics and world knowledge, emphasizing data quality and coverage rather than blindly expanding token counts.
Stage‑2: Visual instruction alignment
Continue full‑parameter training on the 22M instruction set plus multi‑source visual instruction corpora such as FineVision to improve task generalization, reasoning organization, and response‑format control.
3) Offline Parallel Data Packing
To reduce padding waste from multimodal sequence‑length variance and improve effective token utilization, we adopt offline parallel packing:
hash‑bucket clustering by sample length or length ranges to cut global sorting/scanning costs
multithreaded concatenation of multiple short samples into fixed‑length sequences close to the target length during data prep
This one‑pass, corpus‑wide pipeline is deterministic and reproducible, avoiding the runtime instability and extra CPU overhead of online dynamic packing. On the 85M pretraining set, it achieves up to ~11× effective padding compression (defined as original total padding tokens / post‑packing total padding tokens) compared to the baseline.
4) Hybrid Parallelism and Efficient Long‑Context Training
On the training side, we use hybrid parallelism and long‑context optimizations—tensor parallelism (TP) + pipeline parallelism (PP) + sequence/context parallelism with a distributed optimizer—to improve compute utilization and memory efficiency at cluster scale. We also adopt a native‑resolution strategy to preserve structural details in charts, documents, and dense text regions, avoiding information loss from uniform resizing.
On a 128×A800 cluster, Stage‑1.5 for an 8B model (85M samples, native resolution) completes in about 3.7 days, balancing throughput and cost.
Open-Source Resources
We open-source LLaVA-OneVision-1.5 to facilitate future development of LMMs in the community
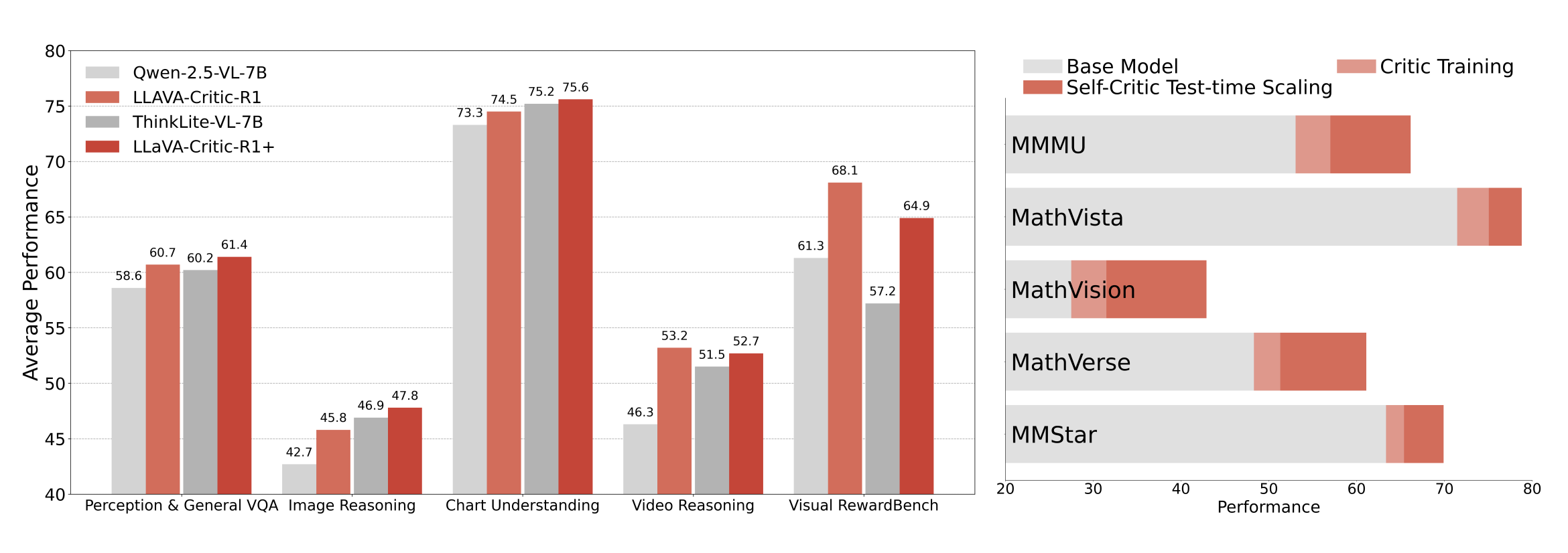
Figure 1: LLaVA-Critic-R1 is trained on top of the base model Qwen-2.5-VL-7B. Building upon a stronger reasoning VLM, ThinkLite-VL-7B, we further develop LLaVA-Critic-R1+ by applying the same RL critic training procedure. **Left**: Performance comparison of LLaVA-Critic-R1 with other base and reasoning VLMs on multiple visual reasoning, visual understanding, and visual reward benchmarks. LLaVA-Critic-R1 not only significantly outperforms other models in critic performance, but also demonstrates stronger policy capabilities. **Right**: Performance improvement of critic training and test-time self-critic scaling on five common visual reasoning and visual understanding benchmarks. Critic training alone significantly improves the base model's performance. Building upon this, leveraging the dual policy and critic capabilities of LLaVA-Critic-R1 for a 'Best-of-128' self-critic scaling procedure at test time leads to a further substantial boost in performance.
Breaking the Critic-Policy Divide
In vision-language modeling, critic models are typically trained to evaluate outputs—assigning scalar scores or pairwise preferences—rather than to generate responses. This separation from policy models, which produce the responses, is so entrenched that critics are rarely considered for direct policy use.
LLaVA-Critic-R1 challenges this convention. We propose to reorganize preference-labeled critic datasets into verifiable training signals and perform reinforcement learning directly on a base generative model, producing a multimodal critic trained to optimize preference judgments while retaining full generation ability.
Surprising Dual Excellence
LLaVA-Critic-R1 emerges not only as a top-performing critic but also as a competitive policy model—matching or surpassing specialized reasoning VLMs trained with in-domain data across 26 visual reasoning and understanding benchmarks, with an average gain of +5.7% over its base model (Qwen-2.5-VL-7B).
Extending this approach to existing strong reasoning VLMs yields LLaVA-Critic-R1+, which further advances policy performance without sacrificing critic quality, achieving a state-of-the-art 71.9 on MMMU at the 7B scale.
Self-Critique at Test Time
The enhanced critic ability benefits inference significantly. Applying self-critique at test time yields an average +13.8% improvement on five representative reasoning tasks without additional training. This demonstrates the power of unified critic-policy models for creating self-improving systems.
Technical Innovation
Our approach centers on three key innovations:
Data Reorganization: We transform preference-labeled critic datasets into verifiable training signals suitable for reinforcement learning.
GRPO Training: We apply Group Relative Policy Optimization directly on generative models, enabling them to learn from critic data while maintaining generation capabilities.
Unified Architecture: We maintain a single model for both critic and policy functions, eliminating the traditional separation between evaluation and generation.
Model Performance
LLaVA-Critic-R1 demonstrates strong performance across diverse benchmarks:
Visual Reasoning: Competitive performance with specialized models on complex reasoning tasks
Critic Evaluation: Top-tier preference judgment and scalar scoring capabilities
Generation Quality: Maintained fluency and coherence with strong instruction following
The model comes in two variants:
LLaVA-Critic-R1: Base model trained from Qwen-2.5-VL-7B
LLaVA-Critic-R1+: Extended approach applied to strong reasoning VLMs
Implications for the Field
Our results reveal that RL training on critic data can produce a unified model excelling at both evaluation and generation, offering a simple path toward scalable, self-improving multimodal systems. This work demonstrates that the traditional separation between critics and policies is not necessary—a single model can excel at both tasks simultaneously.
Project Resources
Access code, models, and research paper for LLaVA-Critic-R1
Multimodal-SAE: First demonstration of SAE-based feature interpretation in Large Multimodal Models
Overview
For the first time in the multimodal domain, we demonstrate that features learned by Sparse Autoencoders (SAEs) in a smaller Large Multimodal Model (LMM) can be effectively interpreted by a larger LMM. Our work introduces the use of SAEs to analyze the open-semantic features of LMMs, providing a breakthrough solution for feature interpretation across various model scales.
Inspiration and Motivation
This research is inspired by Anthropic’s remarkable work on applying SAEs to interpret features in large-scale language models. In multimodal models, we discovered intriguing features that:
Correlate with diverse semantics across visual and textual modalities
Can be leveraged to steer model behavior for precise control
Enable deeper understanding of LMM functionality and decision-making
Technical Approach
SAE Training Pipeline
The Sparse Autoencoder (SAE) is trained using a targeted approach:
Integration Strategy - SAE integrated into a specific layer of the model
Frozen Architecture - All other model components remain frozen during training
Training Data - Utilizes LLaVA-NeXT dataset for comprehensive multimodal coverage
Feature Learning - Learns sparse, interpretable representations of multimodal features
Auto-Explanation Pipeline
Our novel auto-explanation pipeline analyzes visual features through:
Activation Region Analysis - Identifies where features activate in visual inputs
Semantic Correlation - Maps features to interpretable semantic concepts
Cross-Modal Understanding - Leverages larger LMMs for feature interpretation
Automated Processing - Scalable interpretation without manual annotation
Feature Steering and Control
Demonstration of feature steering: These learned features can be used to control model behavior and generate desired outputs
Behavioral Control Capabilities
The learned features enable precise model steering by:
Selective Feature Activation - Amplifying specific semantic features
Behavioral Modification - Directing model attention and responses
Interpretable Control - Understanding why specific outputs are generated
Fine-Grained Manipulation - Precise control over model behavior
Key Contributions
🔬 First Multimodal SAE Implementation
Pioneering application of SAE methodology to multimodal models, opening new research directions in mechanistic interpretability.
🎯 Cross-Scale Feature Interpretation
Demonstration that smaller LMMs can learn features interpretable by larger models, enabling scalable analysis approaches.
🎮 Model Steering Capabilities
Practical application of learned features for controllable model behavior and output generation.
🔄 Auto-Explanation Pipeline
Automated methodology for interpreting visual features without requiring manual semantic labeling.
Research Impact
Mechanistic Interpretability Advancement
This work represents a significant advancement in understanding how multimodal models process and integrate information across modalities.
Practical Applications
Model Debugging - Understanding failure modes and biases
Controllable Generation - Steering model outputs for specific applications
Safety and Alignment - Better control over model behavior
Feature Analysis - Deep understanding of learned representations
Future Directions
Our methodology opens new research avenues in:
Cross-Modal Feature Analysis - Understanding feature interactions across modalities
Scalable Interpretability - Extending to larger and more complex models
Real-Time Steering - Dynamic control during inference
Safety Applications - Preventing harmful or biased outputs
Technical Details
Architecture Integration
The SAE is carefully integrated to:
Preserve Model Performance - Minimal impact on original capabilities
Capture Rich Features - Learn meaningful sparse representations
Enable Interpretation - Facilitate analysis by larger models
Support Steering - Allow runtime behavioral modification
Evaluation Methodology
Our approach is validated through:
Feature Interpretability - Qualitative analysis of learned features
Steering Effectiveness - Quantitative measurement of behavioral control
Cross-Model Validation - Testing interpretation across different model sizes
Semantic Consistency - Verifying feature stability and meaning
Open Source Resources
Comprehensive resources for the research community to reproduce and extend our multimodal SAE work
Multimodal-SAE represents a breakthrough in multimodal mechanistic interpretability, providing the first successful demonstration of SAE-based feature interpretation in the multimodal domain. Our work enables:
Deeper Understanding of how LMMs process multimodal information
Practical Control over model behavior through feature steering
Scalable Interpretation methods for increasingly complex models
Foundation Research for future advances in multimodal AI safety and control
This research establishes a new paradigm for understanding and controlling Large Multimodal Models, with significant implications for AI safety, controllability, and interpretability research.
The development of video large multimodal models (LMMs) has been hindered by the difficulty of curating large amounts of high-quality raw data from the web. To address this, we consider an alternative approach, creating a high-quality synthetic dataset specifically for video instruction-following, namely LLaVA-Video-178K. This dataset includes key tasks such as detailed captioning, open-ended question-answering (QA), and multiple-choice QA. By training on this proposed dataset, in combination with existing visual instruction tuning data, we introduce LLaVA-Video, a new video LMM. Our experiments demonstrate that LLaVA-Video achieves strong performance across various video benchmarks, highlighting the effectiveness of our dataset. We plan to release the dataset, its generation pipeline, and the model checkpoints.
Video Instruction-Following Data Synthesis
A high-quality dataset for video instruction-tuning is crucial for developing effective video-language models. We identify a key factor in building such datasets: ensuring richness and diversity in both video content and its language annotations. We perform comprehensive survey on the existing video benchmarks, covering across various public video captioning and question-answering datasets, then identify ten unique video sources that contribute to over 40 video-language benchmarks. From each source, we select videos that exhibit significant temporal dynamics. To maintain diversity in the annotations, we establish a pipeline capable of generating detailed captions for videos of any length. Additionally, we define 16 types of questions that guide GPT-4o in creating question-answer pairs to assess the perceptual and reasoning skills of the video-language models.
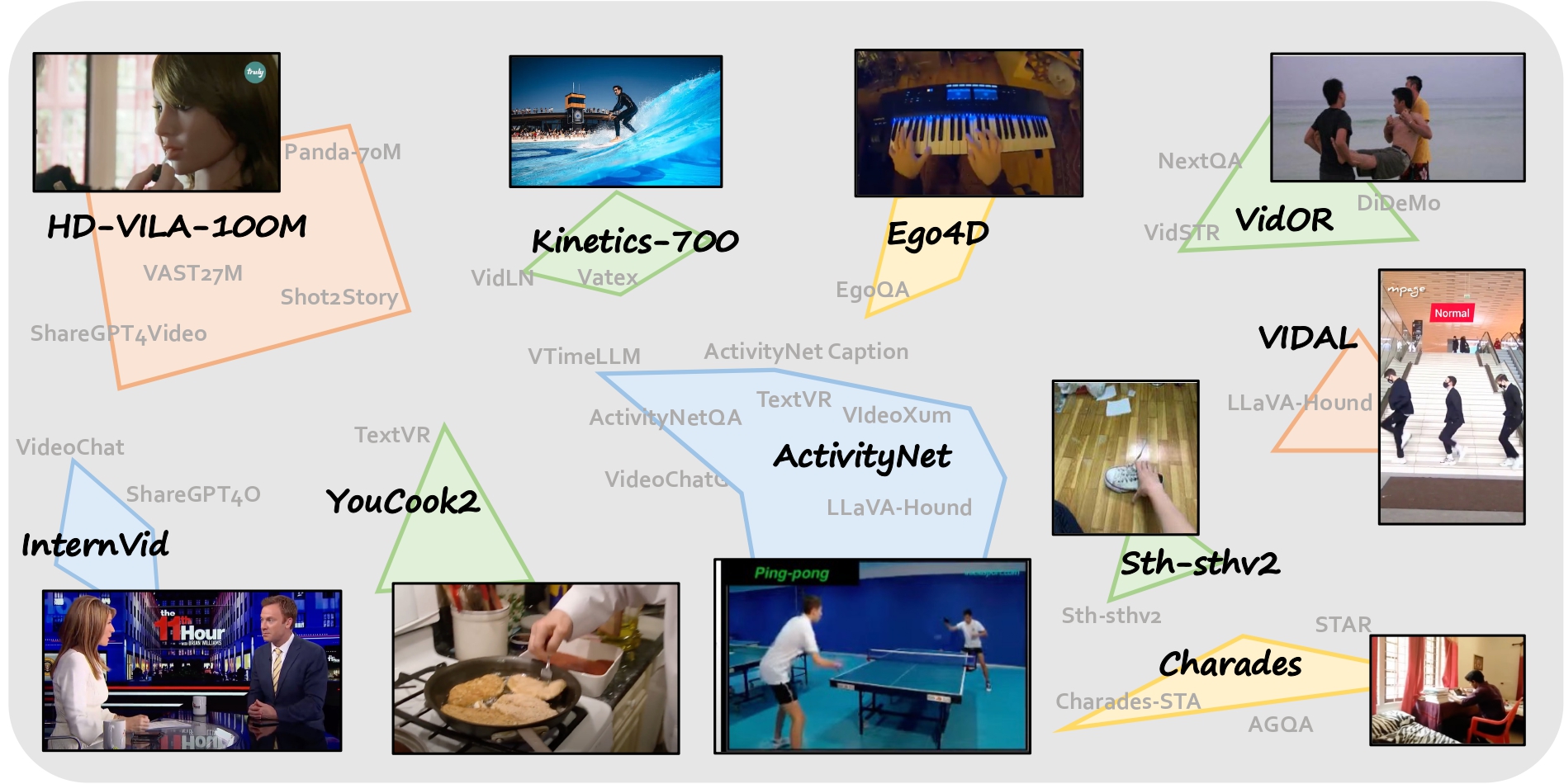
Video Sources
Video sources in the proposed LLaVA-Video-178K. The relationship between 10
video sources we have utilized and other existing video-language datasets.
We noticed that although different video-language datasets focus on various video understanding tasks , most are sourced from ten main video sources, which offer a wide range of video data from different websites, viewpoints, and domains. The relationship between these ten selected video datasets and others is shown in figure below. We select the dynamic video from these source, we detail the video selection logic in the paper.
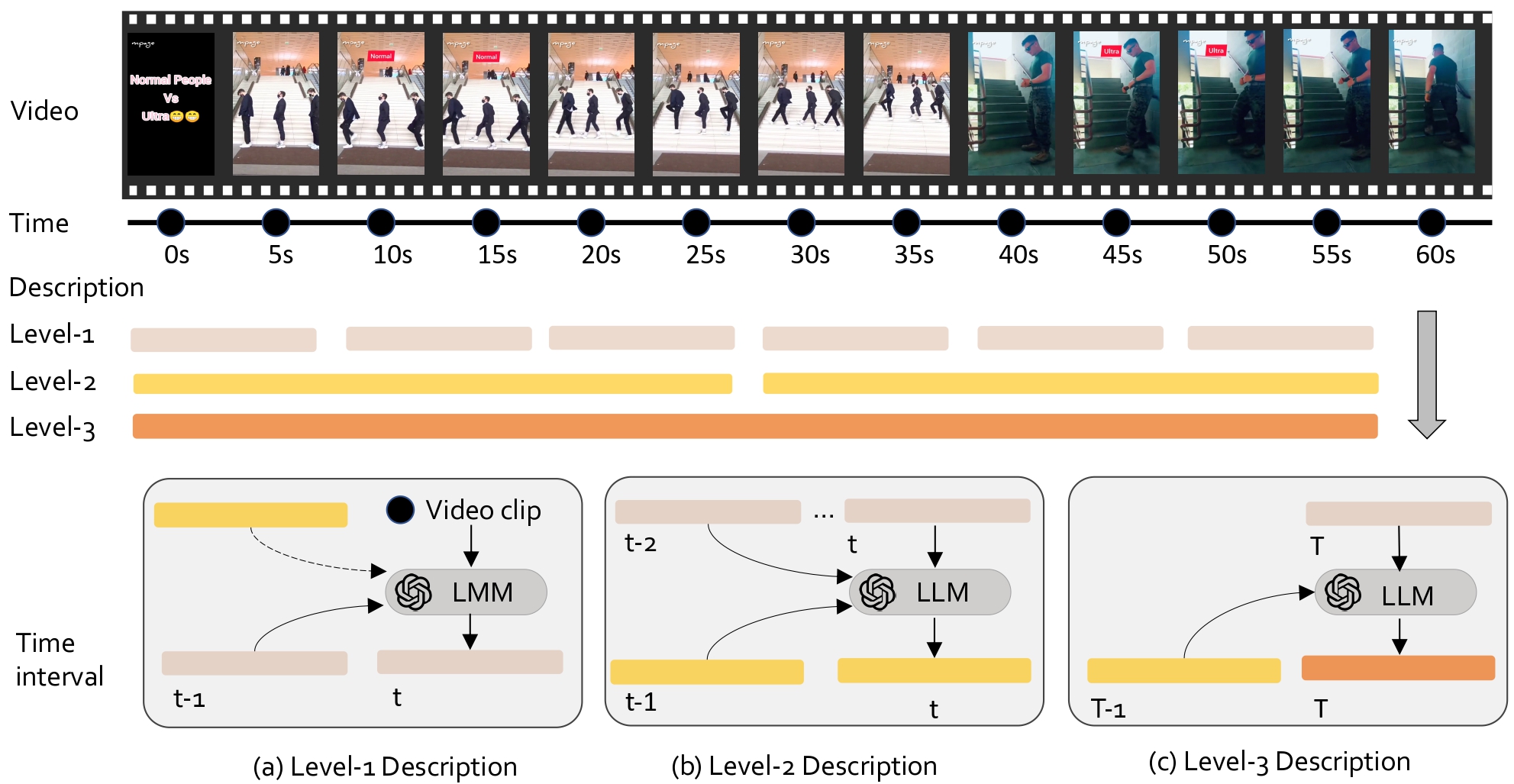
Automated Generation for Video Detail Description
The video detail description creation pipeline. A three-level creation pipeline is considered,
with each level developed via a recurrent approach. Note that t is the index of time internal at its own level,
and T is the last time internal index
For selected videos, we use GPT-4o to systematically describe their content. We start by sampling video frames at one frame per second (fps). However, due to the input size constraints of GPT-4o, we cannot use all sampled frames. Instead, we describe the videos sequentially, as shown in figure below. We create descriptions at three distinct levels, detailed below.
Automated Generation for Video Question Answering
In addition to detailed video descriptions, our dataset includes a variety of question-answer pairs designed for complex interactions. This setup improves the video understanding model’s ability to handle real-life queries. We refer to public video question-answering benchmarks to organize these questions into 16 specific categories, as shown in Figure 3. Given a detailed video description, we use GPT-4o to generate at most one question-answer pair for each type of question. Please refer to the paper for more details of the question types and the generation process.
Dataset Statistics
We carefully select from our collected data sources to form a balanced and comprehensive collection, resulting in a total of 178K videos and 1.3M instruction-following samples. This includes 178K captions, 960K open-ended QAs, and 196K multiple-choice QAs.
Dataset Comparison
We provide a comparison of high-quality instruction-following video-language datasets, with a focus on synthetic data created with strong AI models, as shown in Table 1.
A broad collection of dynamic videos. In terms of video sources, although LLaVA-Hound contains the largest number of videos, 44% of its video data are sourced from WebVid, where most videos are static. ShareGPT4Video includes 30% of its videos from Pexels, ,Pixabay, and Mixkit, which are aesthetically good but also mostly static. Additionally, the majority of its videos come from Panda-70M, which are short clips from longer videos, suggesting simpler plots. In contrast, we carefully select video sources that offer dynamic, untrimmed videos with complex plots, which are crucial for developing a powerful video understanding model.
High frames per second. Regarding frame sampling in language annotations, the proposed dataset considers 1 FPS, while other datasets consider much lower FPS. LLaVA-Hound uniformly samples 10 frames from videos of any length. The average FPS is 0.008, which may miss some fine details. ShareGPT4Video picks key frames using CLIP based on frame uniqueness. This method might also miss subtle changes in the video because CLIP embeddings do not capture fine-grained dynamics well. Our method samples FPS=1 without using key frame selection algorithms, ensuring that detailed temporal information can be expressed in annotations with high coverage.
Diverse tasks. The proposed dataset considers three common task types, including caption, free-form, and closed-form QA, while existing datasets only consider a subset. Meanwhile, the quality and number of samples in our dataset is higher.
LLaVA-OneVision: A unified model for single-image, multi-image, and video understanding
Overview
We present LLaVA-OneVision, a family of open large multimodal models (LMMs) developed by consolidating our insights into data, models, and visual representations in the LLaVA-NeXT blog series. LLaVA-OneVision is the first single model that can simultaneously push the performance boundaries of open LMMs in three important computer vision scenarios: single-image, multi-image, and video scenarios.
Key Features
Unified Architecture
LLaVA-OneVision is designed to have a similar maximum visual token count across different scenarios, enabling flexible extension to multiple visual signal types while maintaining consistent performance.
Model Sizes
0.5B parameters - Lightweight deployment
7B parameters - Balanced performance
72B parameters - State-of-the-art capabilities
Emerging Capabilities
The design of LLaVA-OneVision enables strong transfer learning across different modalities and scenarios, yielding impressive emerging capabilities:
1. Cross-Scenario Understanding
Seamlessly process and understand content across single images, multiple images, and videos within a unified framework.
2. Advanced Visual Analysis
Diagram and table interpretation - Understanding complex visual structures
Multi-screenshot interaction - Analyzing relationships across multiple screens
Set-of-mark object referencing - Precise object identification and tracking
Video analysis and comparison - Deep understanding of video content
Multi-camera video interpretation - Processing footage from multiple viewpoints
Detailed video subject description - Rich, contextual video narration
Strong Transfer Learning
Importantly, the design of LLaVA-OneVision allows strong transfer learning across different modalities/scenarios. In particular, strong video understanding and cross-scenario capabilities are demonstrated through task transfer from images to videos, showcasing the model’s ability to generalize learned representations across visual domains.
Open-Source Resources
Complete LLaVA-OneVision resources to facilitate future development of LMMs in the community