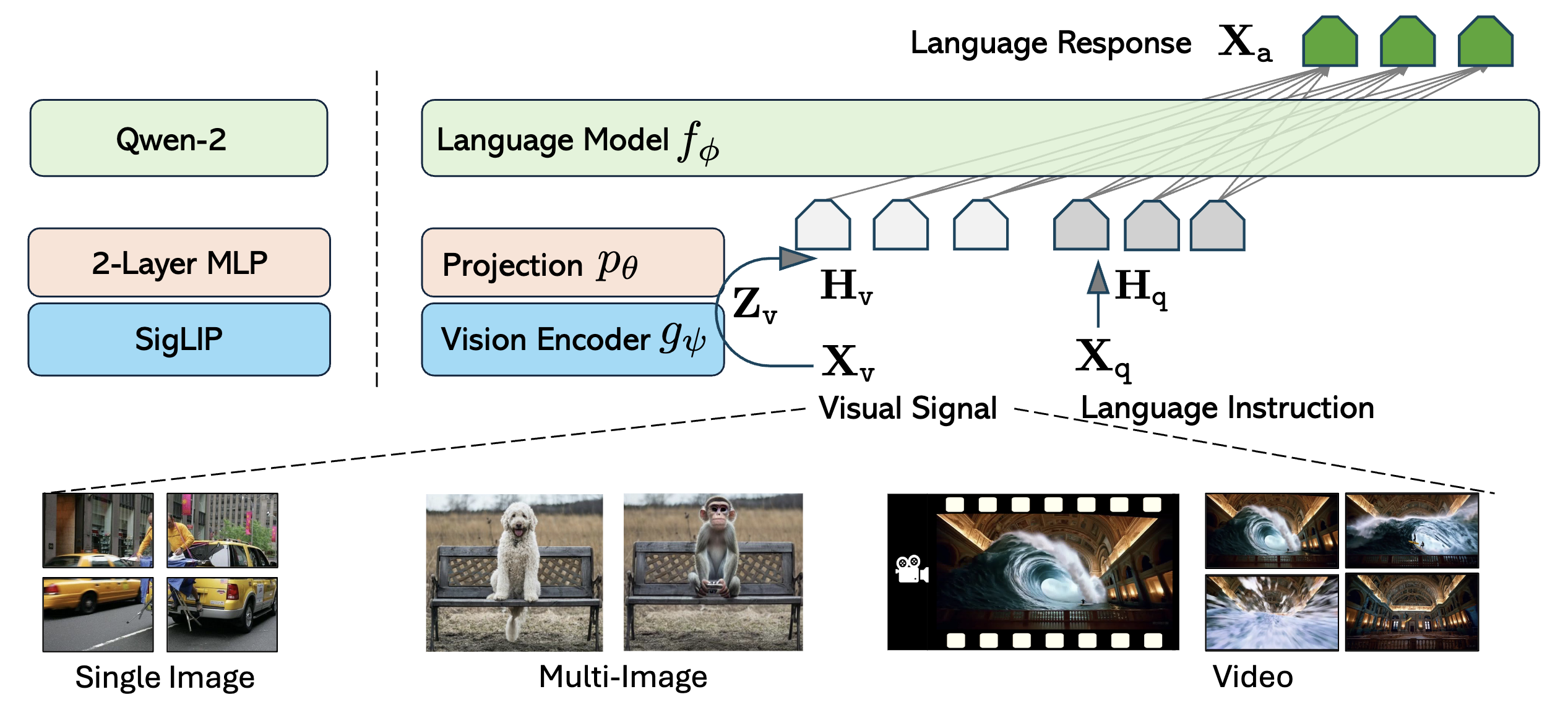
Overview
Our contributions are threefold:
(1) LongVT: An End-to-End Agentic Framework for “Thinking with Long Videos”
We introduce a novel paradigm that natively interleaves multimodal tool-augmented Chain-of-Thought (CoT) with on-demand clip inspection over hours-long videos, thereby enabling large multimodal models (LMMs) to perform more effective and reliable long-video reasoning.
(2) VideoSIAH: A Fine-Grained Data Suite for Evidence-Sparse Long-Video Reasoning
We construct a scalable data pipeline that produces diverse and high-quality question-answering (QA) data and tool-integrated reasoning traces, and a dedicated benchmark under a video segment-in-a-haystack setting.
(3) LongVT-7B-RFT: A State-of-the-Art Baseline with Invaluable Insights
Through extensive quantitative comparisons, systematic ablations on data recipes, training strategies, and design choices, as well as in-depth analyses of training dynamics, we establish and open-source a powerful baseline model with “thinking with long videos” capabilities.

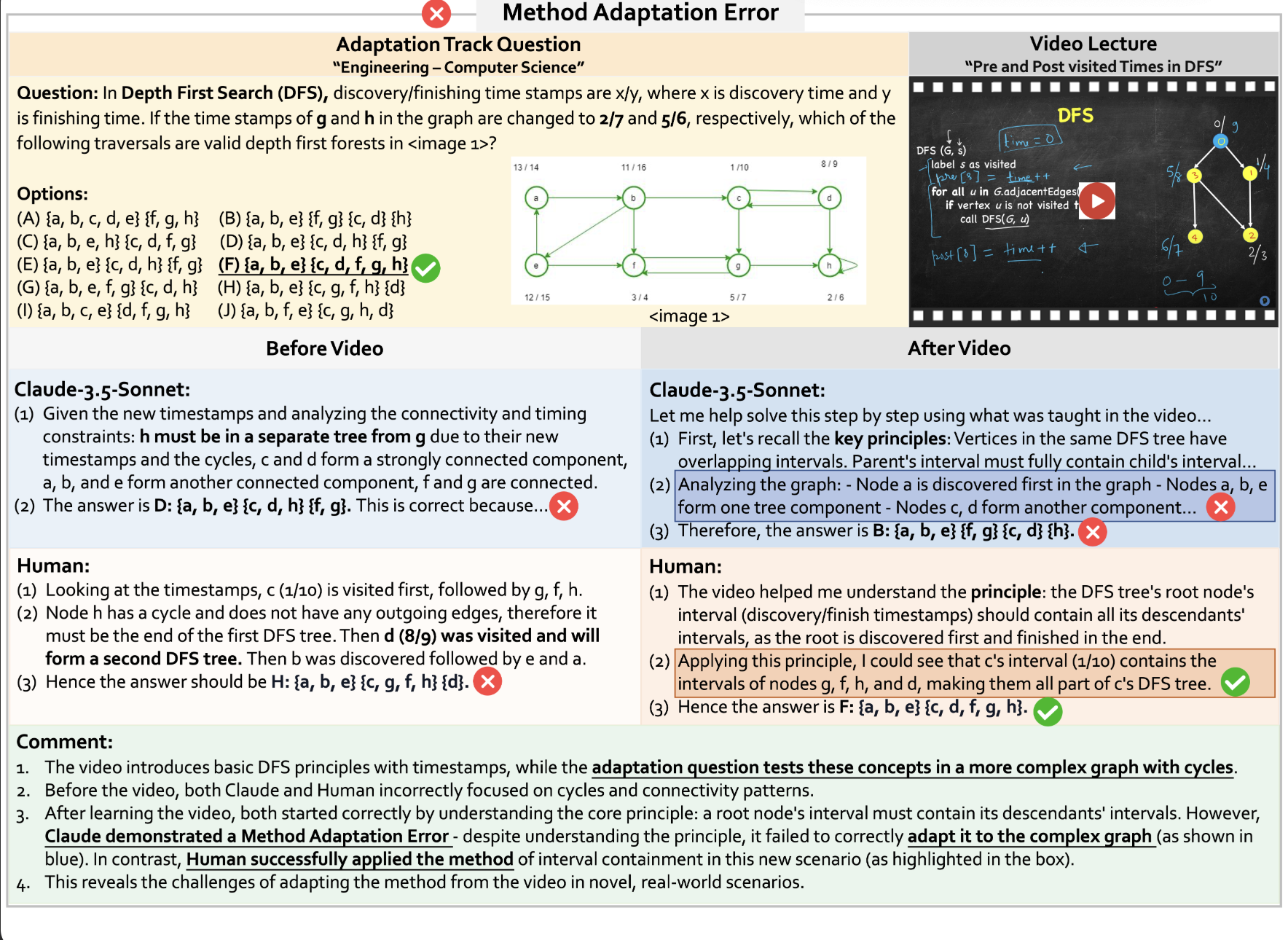
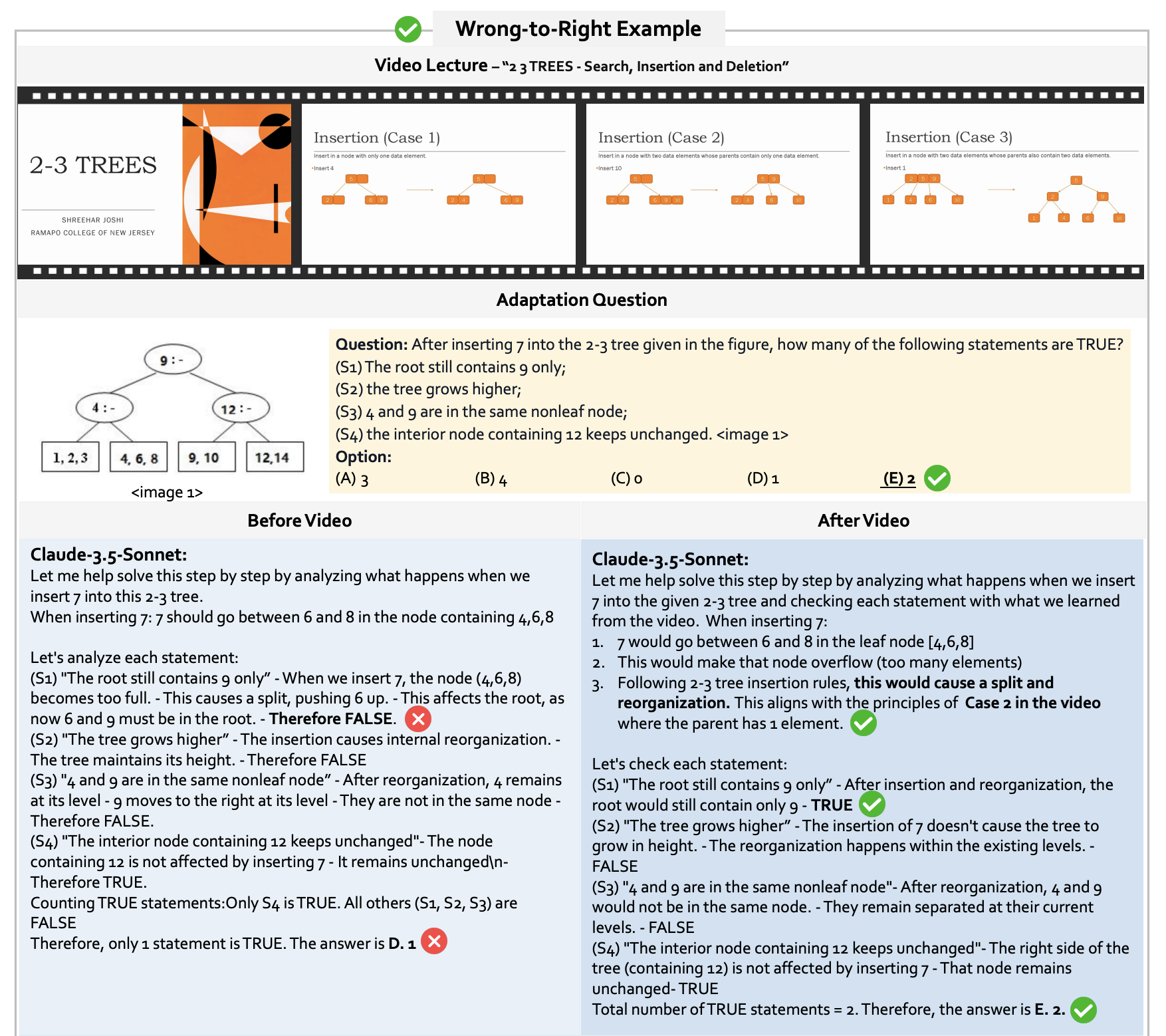
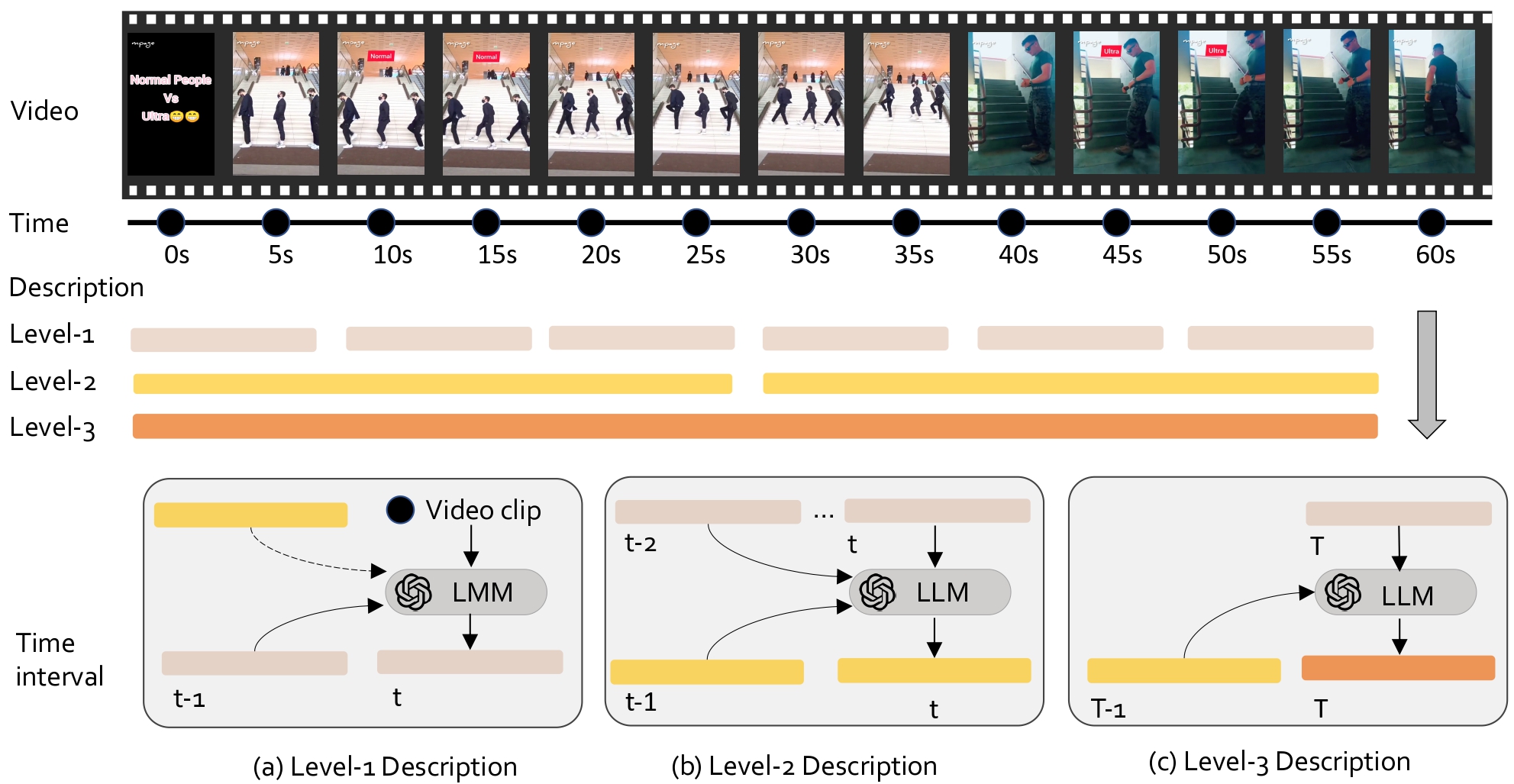
Interleaved Multimodal Chain-of-Tool-Thought (iMCoTT). Compared to prior text-based CoT reasoning, iMCoTT in our proposed LongVT can natively perform self-reflection via calling crop_video(start_time, end_time) tool. It proposes a time window after a global preview, proactively fetches the corresponding short clip, rethinks based on the new evidence, and determines whether to refine or answer directly. Such tool-augmented reasoning behaviors ground each step in what is actually seen rather than blindly rephrasing in text-only CoT, which mitigates hallucination and leads to enhanced temporal localization and answer correctness.
Motivation of VideoSIAH
Long-video reasoning presents a fundamentally different challenge from previous video QA settings: LMMs must locate sparse, fine-grained, and causally decisive moments embedded within hours-long content. However, existing LMMs are mostly trained with coarse-grained and clip-level data. This mismatch leaves modern LMMs lacking the supervision needed to learn how temporal hypotheses are formed, verified, or revised—a critical yet underexplored capability for agentic long-video reasoning.
Moreover, most existing video understanding benchmarks only offer multiple-choice QAs, which can be solved without genuine temporal grounding and are vulnerable to dataset leakage or shortcut exploitation. To fill this gap, we introduce VideoSIAH, a large-scale, diverse, and high-quality data suite that serves collectively as a training dataset capturing the reasoning dynamics required for video segment-in-a-haystack QA, and a fine-grained evaluation benchmark, VideoSIAH-Eval, with human-in-the-loop validation for long-video open-ended question-answering.
We conduct a rigorous contamination study on the Qwen-VL series across two probing settings: (1) No Visual, where we feed the text prompt without video frames to test for direct memorization; (2) Rearranged Choices, where we randomize the mapping between option labels and their textual content for multiple-choice questions to detect label memorization. Our experimental results reveal significant vulnerabilities in existing benchmarks and highlight the necessity of our proposed VideoSIAH-Eval.
| Setting | VideoMME (w/o sub) | VideoMMMU adapt. | VideoMMMU comp. | VideoMMMU perc. | VideoSIAH-Eval |
|---|---|---|---|---|---|
| Qwen2.5-VL-7B-Instruct | |||||
| Original | 64.3 | 35.7 | 44.3 | 56.7 | 33.8 |
| No Visual | 40.1 | 25.7 | 38.3 | 39.3 | 12.7 |
| Rearranged Choices | 56.0 | 29.7 | 40.3 | 67.0 | - |
| Qwen3-VL-8B-Instruct | |||||
| Original | 69.3 | 40.7 | 60.3 | 71.3 | 46.6 |
| No Visual | 44.1 | 33.7 | 39.3 | 46.7 | 0.00 |
| Rearranged Choices | 69.0 | 36.3 | 47.7 | 69.3 | - |
Contamination Tests for Qwen-VL Series on Long Video Understanding and Reasoning Benchmarks. The VideoSIAH-Eval column shows ”-” entries for Rearranged Choices since our proposed benchmark is fully open-ended QA, where random option-answer mapping is not applicable.
Data Pipeline
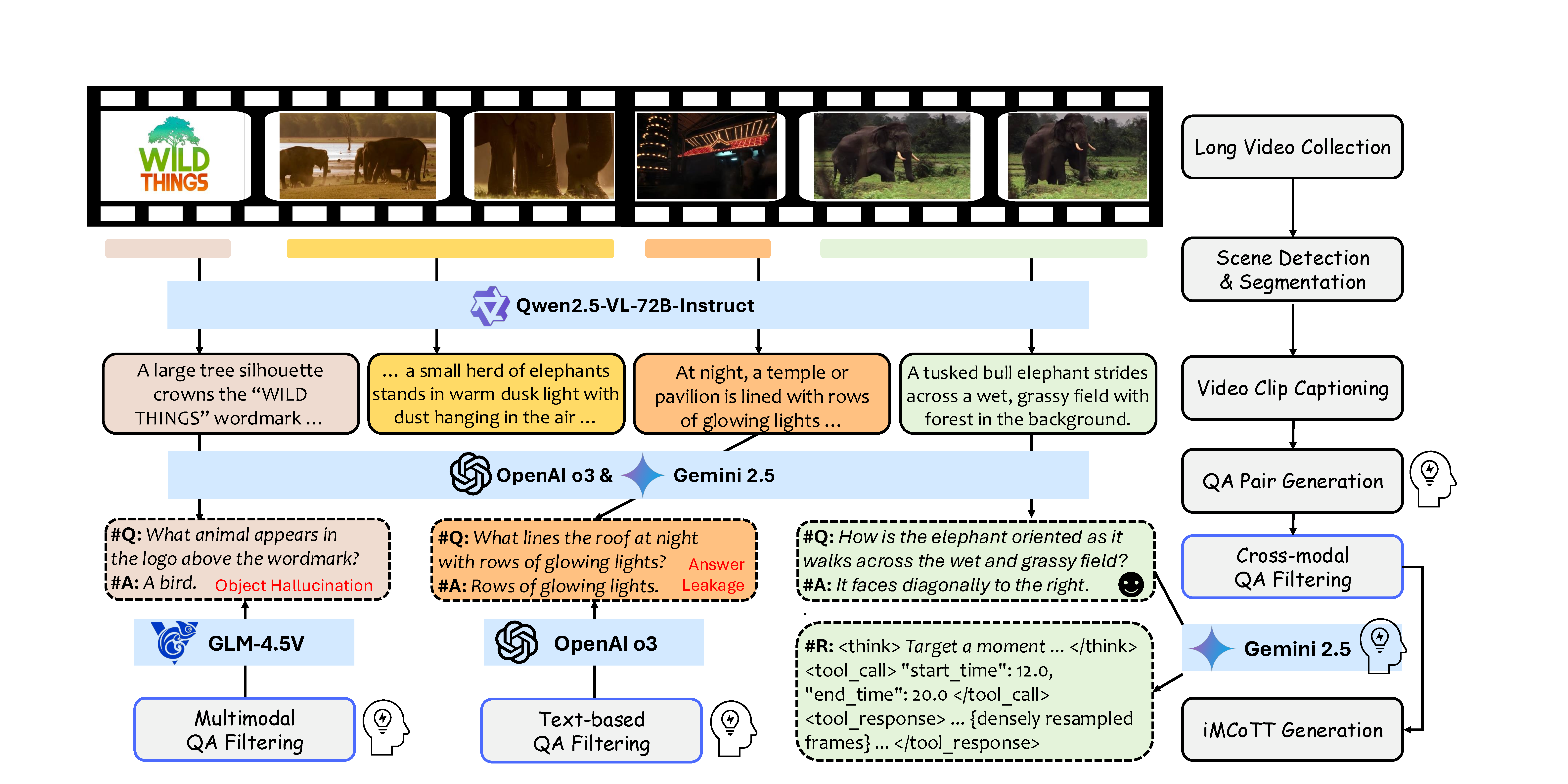
Data Pipeline of VideoSIAH. We construct a semi-automatic data pipeline that integrates several state-of-the-art LMMs to sequentially perform long video segmentation, video clip captioning, segment-in-a-haystack QA generation, cross-modal QA filtering, and iMCoTT generation. Icons with human silhouettes denote human-in-the-loop validation, where annotators inspect a small set of representative failures to refine prompting rules for QA generation, QA filtering, and iMCoTT generation. Note that iMCoTT traces are generated only for the cold-start supervised fine-tuning (SFT) stage, whereas reinforcement learning (RL) operates solely on the filtered QA pairs.
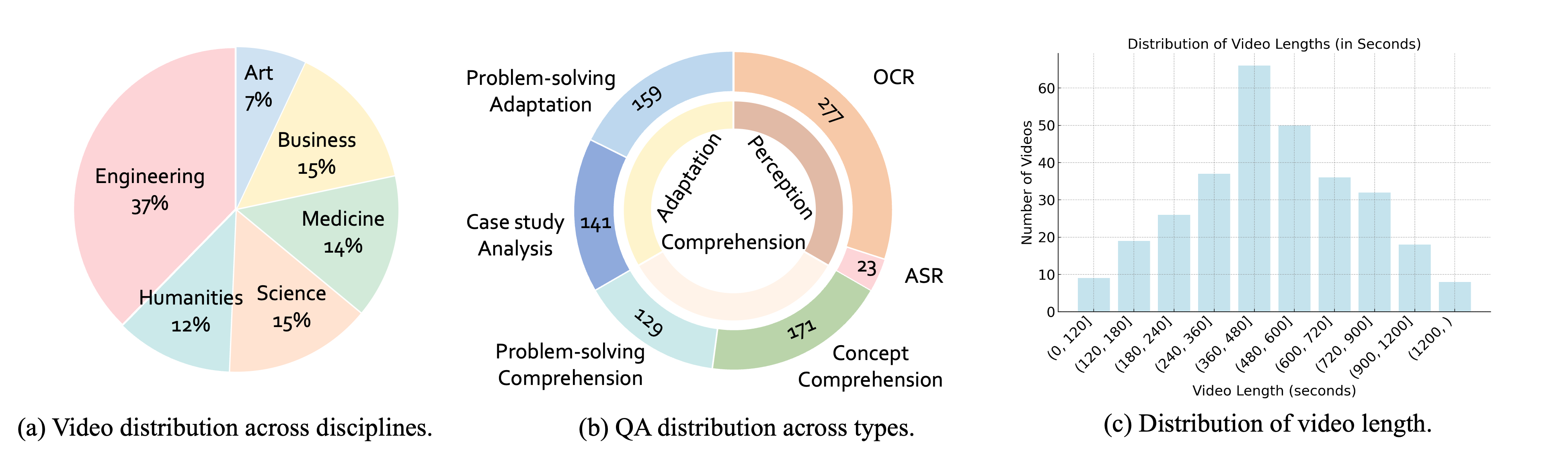
Dataset Statistics
| Split | Source | Purpose | Samples | Total |
|---|---|---|---|---|
| SFT (w/o tool) | LongVideo-Reason CoT | Reasoning-augmented Open-ended QA | 5,238 | 228,835 |
| Video-R1 CoT | Reasoning-augmented Video QA | 165,575 | ||
| Image-based CoT | Reasoning-augmented Image QA | 58,022 | ||
| SFT (w/ tool) | Gemini-distilled iMCoTT | Tool-augmented Open-ended QA | 12,766 | 19,161 |
| Qwen-distilled iMCoTT | Tool-augmented Temporal Grounding | 6,395 | ||
| RL | Gemini-distilled QAs | Open-ended QA over Long Videos | 1,667 | 17,020 |
| RFT | Self-distilled iMCoTT | Agentic Behaviors | 15,353 |
Dataset Statistics of VideoSIAH. Our proposed dataset contains a large-scale of non-tool SFT data, tool-augmented SFT data, RL QAs, and self-distilled reinforcement fine-tuning (RFT) traces.
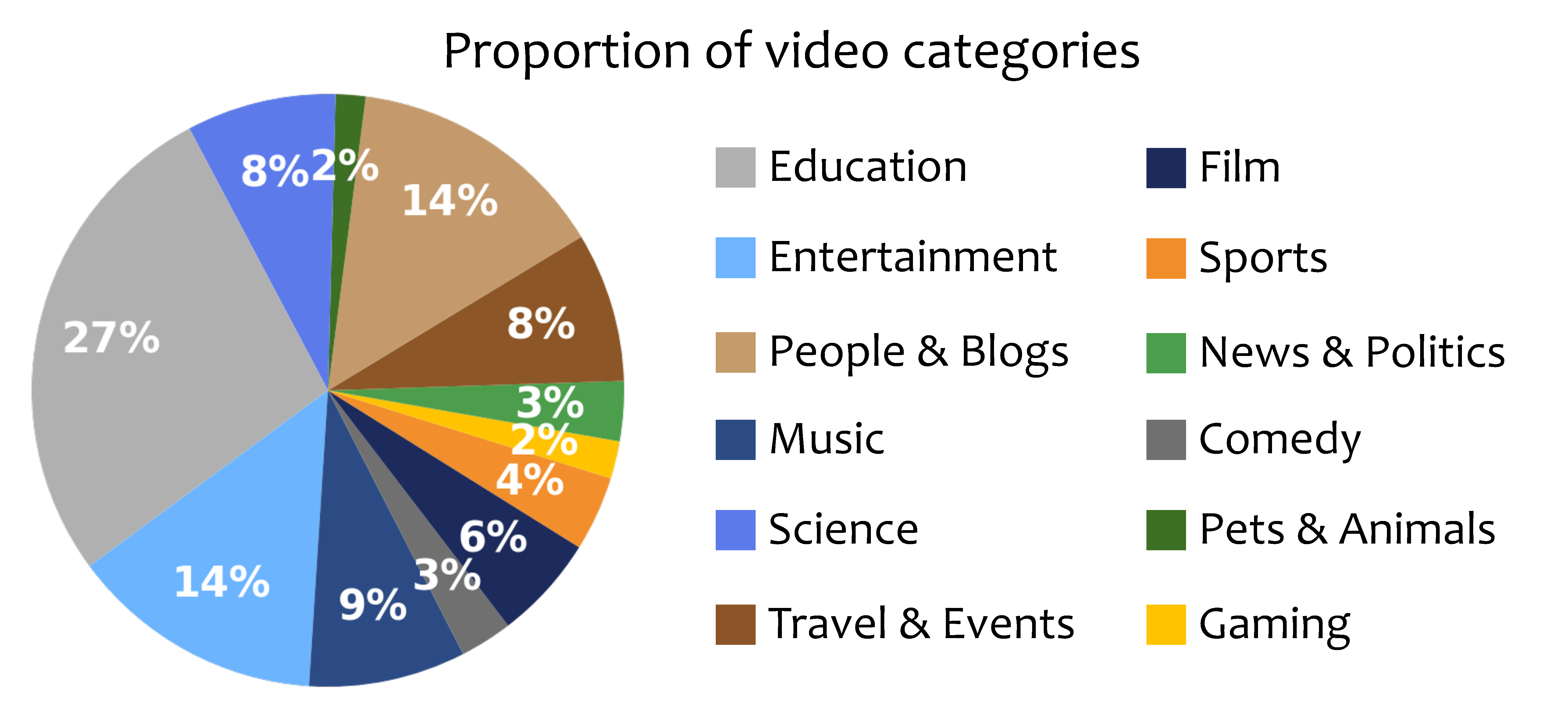
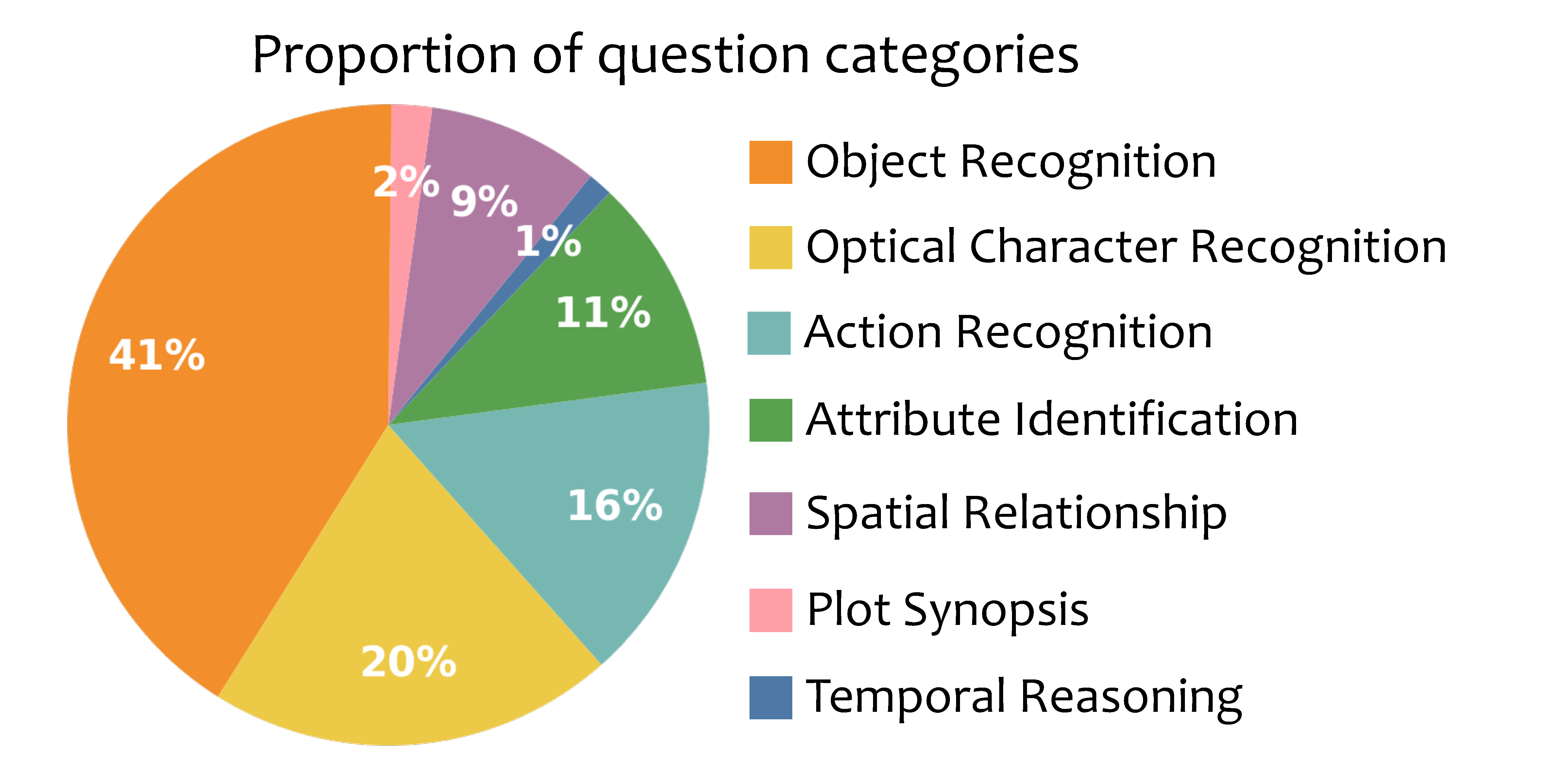
Category Distribution of VideoSIAH-Eval. We present the distribution of video types (left) and question types (right), highlighting the diversity of our proposed benchmark.
Quantitative Comparisons
We compare our LongVT models against proprietary LMMs and state-of-the-art open-source video reasoning models across various long video understanding and reasoning benchmarks.
| Model | Reasoning | Tool | VideoMME | VideoMMMU | LVBench | VideoSIAH-Eval | Avg | ||
|---|---|---|---|---|---|---|---|---|---|
| Prompt | Calling | w/ sub | adapt. | comp. | perc. | ||||
| Proprietary LMMs | |||||||||
| GPT-4o | ✗ | ✗ | 77.2 | 66.0 | 62.0 | 55.7 | 30.8 | 17.4 | 51.5 |
| Gemini 1.5 Pro | ✗ | ✗ | 81.3 | 59.0 | 53.3 | 49.3 | 33.1 | - | 55.2 |
| Open-Source (Sparse Sampling) | |||||||||
| Qwen2.5-VL-7B | ✗ | ✗ | 62.6 | 37.3 | 28.0 | 36.7 | 30.7 | 28.1 | 37.2 |
| Video-R1-7B | ✓ | ✗ | 61.0 | 36.3 | 40.7 | 52.3 | 37.2 | 27.9 | 42.6 |
| VideoRFT-7B | ✓ | ✗ | 60.9 | 36.7 | 42.0 | 53.0 | 34.7 | 26.5 | 42.3 |
| Video-Thinker-7B | ✓ | ✗ | 61.0 | 34.3 | 44.7 | 53.0 | 52.2 | 10.4 | 42.6 |
| LongVT-7B-SFT (Ours) | ✓ | ✓ | 12.5 | 37.7 | 46.0 | 58.3 | 36.0 | 26.8 | 36.2 |
| LongVT-7B-RL (Ours) | ✓ | ✓ | 66.1 | 32.7 | 44.7 | 50.0 | 37.8 | 31.0 | 43.7 |
| Open-Source (Dense Sampling) | |||||||||
| Qwen2.5-VL-7B | ✗ | ✗ | 64.3 | 35.7 | 44.3 | 56.7 | 40.9 | 33.8 | 46.0 |
| Video-R1-7B | ✓ | ✗ | 60.5 | 37.3 | 38.7 | 46.3 | 40.1 | 33.1 | 42.7 |
| VideoRFT-7B | ✓ | ✗ | 49.2 | 37.7 | 40.7 | 48.7 | 18.7 | 26.9 | 37.0 |
| Video-Thinker-7B | ✓ | ✗ | 60.8 | 37.7 | 42.7 | 55.3 | 54.3 | 6.6 | 42.9 |
| LongVT-7B-SFT (Ours) | ✓ | ✓ | 64.9 | 32.3 | 42.0 | 49.7 | 41.1 | 34.8 | 44.1 |
| LongVT-7B-RL (Ours) | ✓ | ✓ | 66.1 | 37.7 | 42.3 | 56.3 | 41.4 | 35.9 | 46.6 |
| LongVT-7B-RFT (Ours) | ✓ | ✓ | 67.0 | 35.7 | 43.7 | 56.7 | 41.3 | 42.0 | 47.7 |
Performance Comparison with Existing Video-Centric LMMs across Various Long Video Understanding and Reasoning Benchmarks. The best and second-best results among open-source models in each column are marked in bold and underlined, respectively.
Ablation Studies
We conduct comprehensive ablation studies to examine the impact of data recipes, training stages, and reward design on model performance.
Data Recipe
| Setting | VideoMME | VideoMMMU | LVBench | VideoSIAH-Eval | Avg | ||
|---|---|---|---|---|---|---|---|
| w/ sub | adapt. | comp. | perc. | ||||
| SFT w/o self-curated iMCoTT | 8.4 | 33.6 | 41.6 | 46.0 | 15.1 | 4.1 | 24.8 |
| SFT w/ self-curated iMCoTT | 64.9 | 32.3 | 42.0 | 49.7 | 41.1 | 34.8 | 44.1 |
| RL w/o self-curated QAs | 55.1 | 30.6 | 42.0 | 45.6 | 38.4 | 30.8 | 40.4 |
| RL w/ self-curated QAs | 66.1 | 37.7 | 42.3 | 56.3 | 41.4 | 35.9 | 46.6 |
Training Stage
| Setting | VideoMME | VideoMMMU | LVBench | VideoSIAH-Eval | Avg | ||
|---|---|---|---|---|---|---|---|
| w/ sub | adapt. | comp. | perc. | ||||
| SFT only | 64.9 | 32.3 | 42.0 | 49.7 | 41.1 | 34.8 | 44.1 |
| RL only | 52.7 | 35.3 | 43.0 | 55.1 | 37.1 | 28.2 | 41.9 |
| SFT+RL | 66.1 | 37.7 | 42.3 | 56.3 | 41.4 | 35.9 | 46.6 |
| SFT+RL+RFT | 67.0 | 35.7 | 43.7 | 56.7 | 41.3 | 42.0 | 47.7 |
Training Dynamics
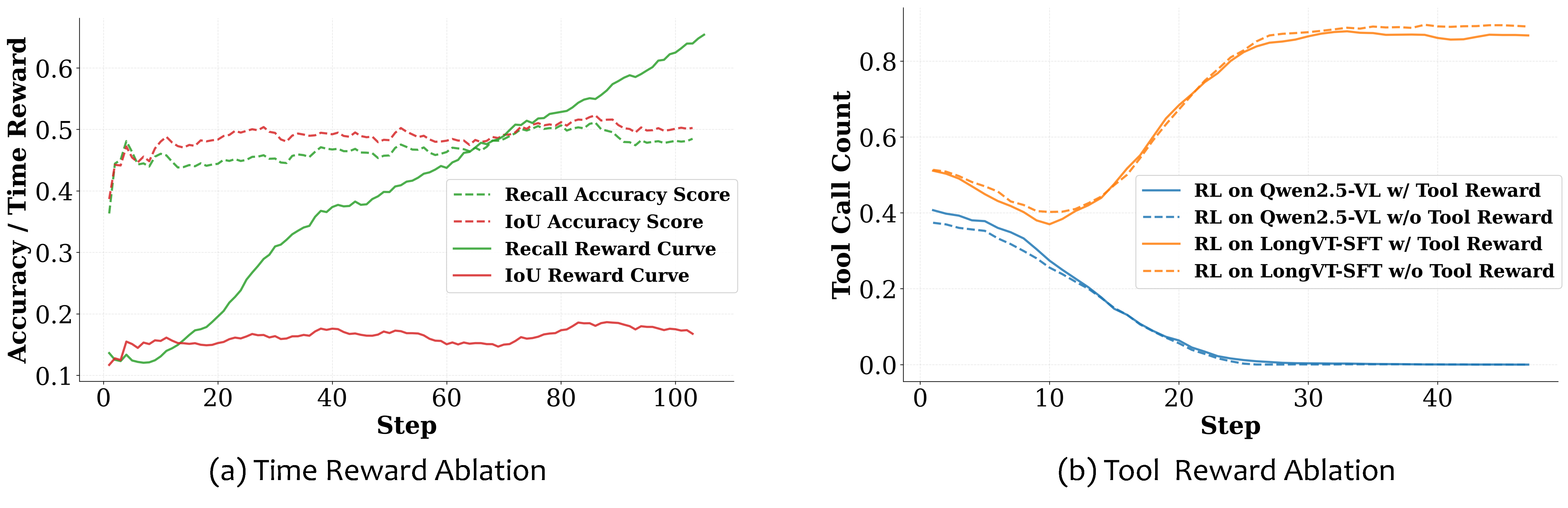
(a) shows training dynamics under different accuracy and time rewards, and (b) shows the effect of tool-call reward on tool usage.
Recall encourages coverage; IoU demands precision. Using Recall as the reward function during RL presents a drawback: the policy can enlarge the predicted span to envelop the ground-truth interval, which monotonically raises the Recall-based score while ignoring boundary quality. This plateau in the curve of Recall Accuracy Score validates our hypothesized reward hacking. In contrast, IoU explicitly penalizes span inflation via the union term, yielding better-aligned boundaries and more disciplined tool use.
Is tool reward really necessary? The Qwen2.5-VL-7B baseline collapses to near-zero tool calls after training in both configurations (w/ and w/o tool reward), indicating that the model does not internalize the tool’s function. After performing cold-start SFT to obtain LongVT-7B-SFT, tool-call frequency rises during training under both configurations and accuracy improves in tandem. Hence, the tool reward is not required for basic competence: once SFT grounds the tool’s semantics, the model learns when and how to invoke the tool.