LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training

Code | Technical Report | Models and Datasets | Demo
High performance, low cost, and strong reproducibility!
LLaVA, proposed in 2023, efficiently connects open-source vision encoders with large language models through low-cost alignment, bringing "see—understand—converse" multimodal capabilities to the open ecosystem. It significantly narrows the gap with top-tier closed models and marks an important milestone in open-source multimodal paradigms.
Starting with a low-cost alignment that bridges "vision encoder + large language model," LLaVA laid the groundwork; LLaVA-1.5 strengthened comprehension with larger, cleaner data and high-resolution inputs; LLaVA-NeXT expanded into OCR, mathematical reasoning, and broader, multi-scenario tasks. It then branched into LLaVA-NeXT-Video for temporal video understanding and multi-frame reasoning, and LLaVA-NeXT-Interleave to support interleaved multi-image–text inputs and cross-image joint reasoning. Ultimately, the line converged in LLaVA-OneVision, which provides a unified interface covering images, documents, charts, multi-image, and video, balancing quality and efficiency.
Although interfaces and architectures for multimodal alignment are trending toward convergence, a truly "reproducible" open-source path still differs from releases that "open weights only." Qwen2.5-VL and InternVL3.5 set strong baselines in OCR, document understanding, mathematical and cross-image reasoning; however, full data inventories, cleaning and mixing ratios, as well as alignment/sampling and training schedules are often only partially disclosed, making end-to-end reproduction difficult. Molmo, with a cleaner data pipeline and meticulous design, approaches strong closed-source baselines across multiple evaluations and human preference settings; Open-Qwen2VL shows that under a more efficient paradigm, strong comparative performance is achievable even when raw multimodal tokens account for a relatively small proportion. The primary gap today lies in the "reproducibility of recipes and engineering details," rather than any single choice of model architecture.
LMMs-Lab, focused on the goals of high performance, low cost, and strong reproducibility, releases on top of the LLaVA‑OneVision framework a fully open, concept-balanced 85M pretraining dataset (LLaVA‑OV‑1.5‑Mid‑Training‑85M) and a carefully curated 22M instruction dataset (LLaVA‑OV‑1.5‑Instruct‑22M). We retain a compact three-stage pipeline (Stage‑1 language–image alignment; Stage‑1.5 concept balancing and high-quality knowledge injection; Stage‑2 instruction tuning), combine offline parallel data packing (up to ~11× padding compression) with Megatron‑LM plus a distributed optimizer, and complete Stage‑1.5 pretraining of an 8B‑scale VL model on 128 A800 GPUs in about four days.
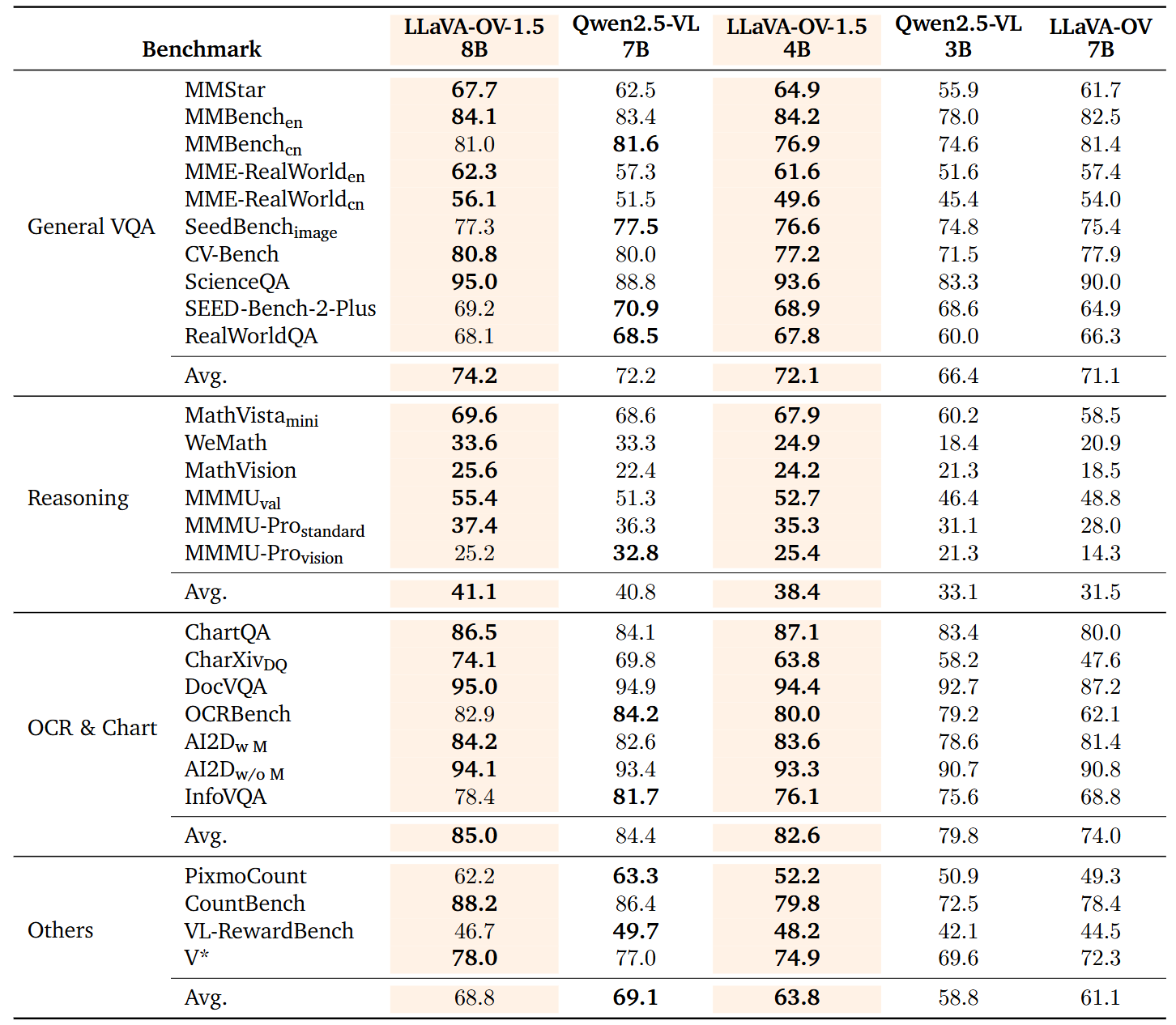
Building on this, we introduce LLaVA‑OneVision‑1.5, which inherits and extends the LLaVA series: it adds RICE‑ViT for native-resolution, region-level fine-grained semantic modeling; strengthens chart/document/structured-scene understanding; continues the compact three-stage paradigm to avoid a lengthy curriculum; and emphasizes "quality–coverage–balance" across the 85M pretraining and 22M instruction sets. Crucially, it delivers truly end-to-end transparent openness—covering data, training and packing toolchains, configuration scripts, logs, and reproducible evaluation commands with their build and execution details—to enable low-cost reproduction and verifiable extension by the community. Experiments show LLaVA‑OneVision achieves competitive or superior performance to Qwen2.5‑VL on multiple public multimodal benchmarks (see the technical report).
Pretraining Dataset (85M) and Concept Balancing
A general-purpose vision–language pretraining dataset (85M) and an instruction-tuning dataset (22M). The 85M pretraining corpus fuses eight heterogeneous sources—COYO-700M, Obelics, DataComp-1B, LAION-CN, ImageNet-21K, SAM-1B, MINT, and Zero250M—yielding roughly 20 million Chinese and 65 million English image–text pairs. To tackle long-tail concept sparsity and noise/missing issues in raw captions, we move beyond raw term frequencies and adopt a feature-driven "concept balancing" strategy: using a MetaCLIP encoder, we embed all images and a 500K-scale concept vocabulary into a shared vector space, retrieve the Top-K most similar concepts for each image, tally concept frequencies, and then apply inverse-frequency weighted resampling. This suppresses high-frequency background classes and boosts rare fine-grained entities, attributes, and scenes, substantially flattening the long-tail distribution. We then use a high-quality captioner to generate aligned bilingual (Chinese/English) augmented descriptions. Systematic experiments show that, under the same or lower token budget, scaling high-quality data combined with concept-balanced sampling delivers significant and reproducible gains in multimodal understanding, long-tail recognition, and instruction generalization.
Instruction Dataset (22M)
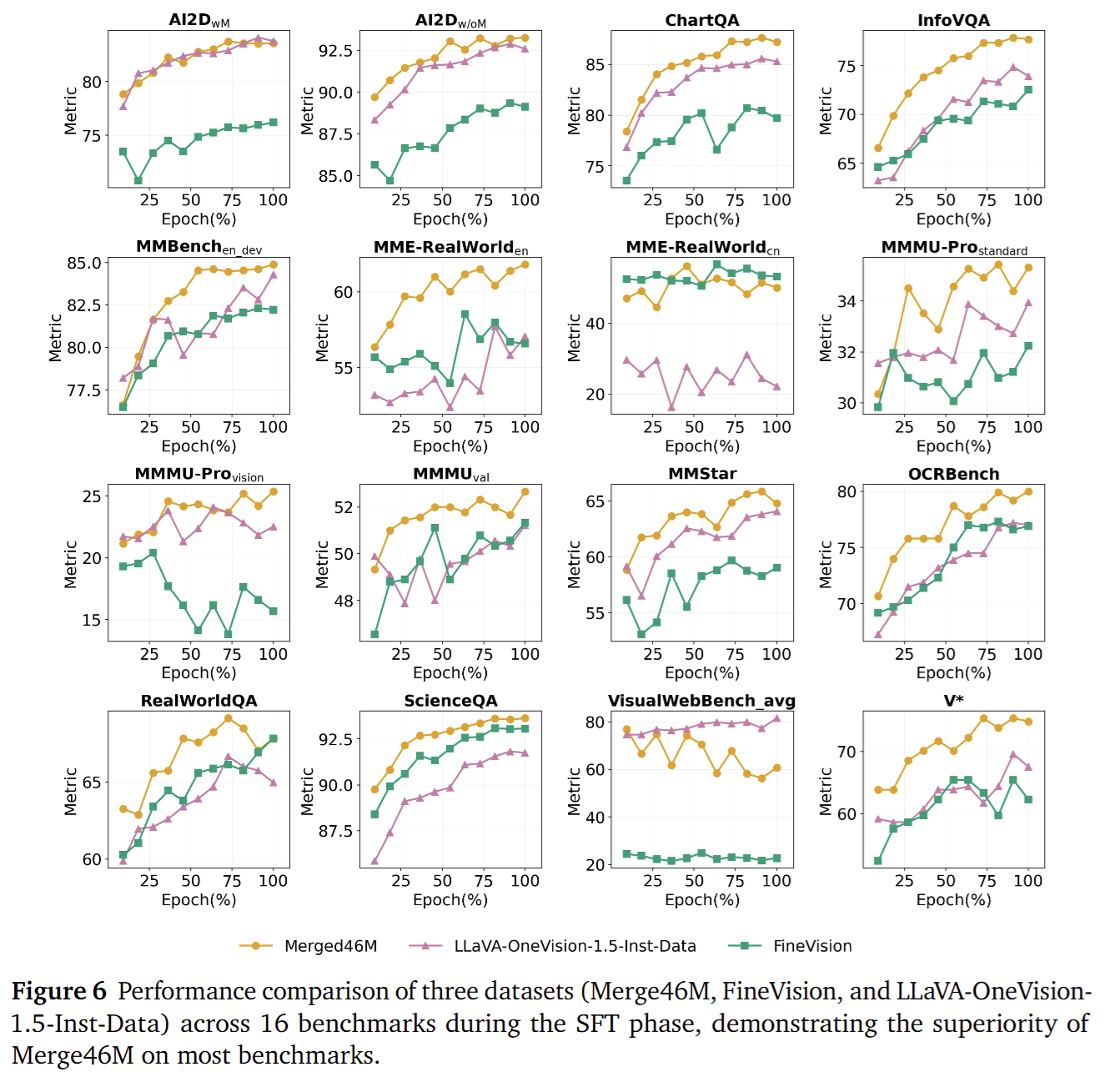
The 22M instruction dataset covers eight categories: Caption, Chart & Table, Code & Math, Domain-specific, General VQA, Grounding & Counting, OCR, and Science. Through multi-source aggregation, format standardization, instruction rewriting, bilingual conversion, template diversification (to reduce homogeneity), and safety filtering, we maintain balanced distributions across categories and difficulty levels. Moreover, augmenting our instruction data with the FineVision dataset yields further performance gains.
Method
1) Visual Encoder Pretraining
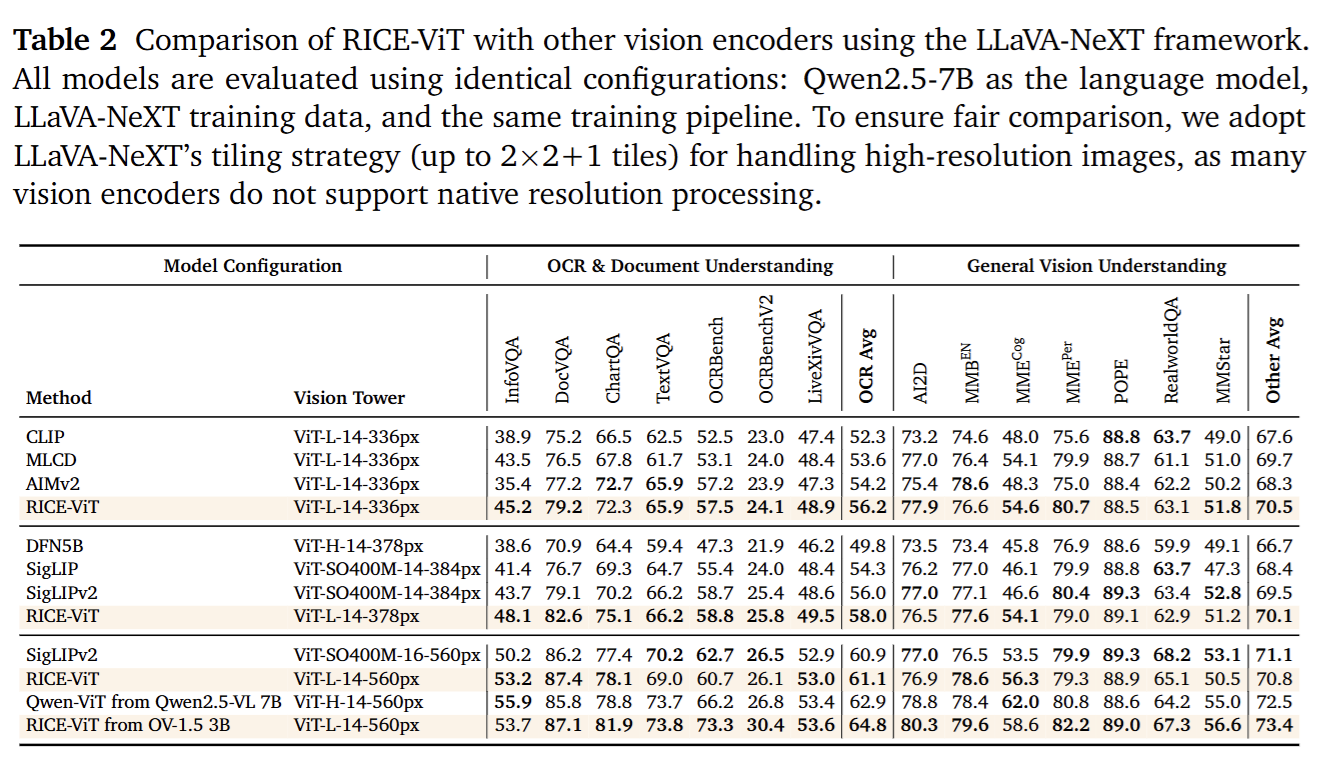
To raise the floor for OCR, tables/documents, region‑level understanding, and downstream instruction reasoning, LLaVA‑OneVision‑1.5 adopts our in‑house MVT v1.5 (RICE‑ViT) as the vision backbone.
Compared to CLIP/SigLIP‑style contrastive models that rely on global alignment only, RICE‑ViT addresses the structural bottleneck of representing an instance with a single global vector by introducing a unified Region Cluster Discrimination mechanism:
- trained on 450M images and 2.4B candidate regions
- explicitly models local entities/text blocks and their context via region‑cluster discrimination plus region‑aware attention
- uses 2D rotary position encoding (2D RoPE) for native multi‑resolution support
Unlike SigLIP2, which relies on multiple specialized losses (SILC, TIPS, LocCa, etc.), we use a single clustering‑discrimination paradigm to simultaneously strengthen general semantics, OCR recognition, and localization, yielding a simpler, more maintainable training/inference pipeline.
During multimodal fusion, a lightweight projection followed by full‑parameter joint training seamlessly plugs this fine‑grained semantic foundation into the language model, reducing redundant adapters and improving cross‑task transfer efficiency.
2) Three‑Stage Learning Pipeline
-
Stage‑1: Language–image alignment
Train the visual projection layer on the LLaVA‑1.5 558K dataset to map visual encoder outputs into the LLM's token embedding space, with controlled parameter updates for fast, stable convergence. -
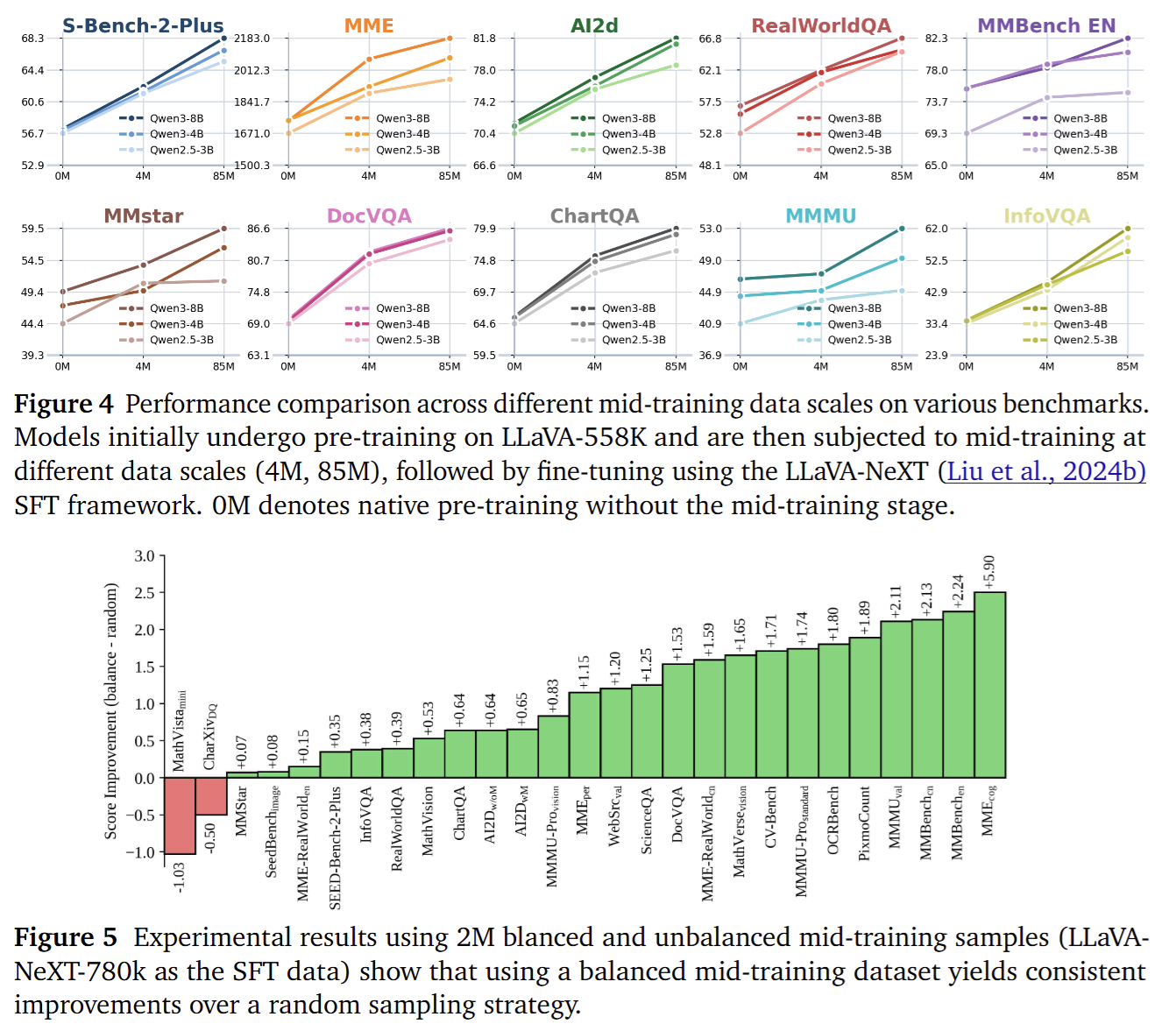
Stage‑1.5: Mid‑stage pretraining with high‑quality knowledge
Full‑parameter training on the concept‑balanced 85M pretraining set to inject broad visual semantics and world knowledge, emphasizing data quality and coverage rather than blindly expanding token counts. -
Stage‑2: Visual instruction alignment
Continue full‑parameter training on the 22M instruction set plus multi‑source visual instruction corpora such as FineVision to improve task generalization, reasoning organization, and response‑format control.
3) Offline Parallel Data Packing
To reduce padding waste from multimodal sequence‑length variance and improve effective token utilization, we adopt offline parallel packing:
- hash‑bucket clustering by sample length or length ranges to cut global sorting/scanning costs
- multithreaded concatenation of multiple short samples into fixed‑length sequences close to the target length during data prep
This one‑pass, corpus‑wide pipeline is deterministic and reproducible, avoiding the runtime instability and extra CPU overhead of online dynamic packing. On the 85M pretraining set, it achieves up to ~11× effective padding compression (defined as original total padding tokens / post‑packing total padding tokens) compared to the baseline.
4) Hybrid Parallelism and Efficient Long‑Context Training
On the training side, we use hybrid parallelism and long‑context optimizations—tensor parallelism (TP) + pipeline parallelism (PP) + sequence/context parallelism with a distributed optimizer—to improve compute utilization and memory efficiency at cluster scale. We also adopt a native‑resolution strategy to preserve structural details in charts, documents, and dense text regions, avoiding information loss from uniform resizing.
On a 128×A800 cluster, Stage‑1.5 for an 8B model (85M samples, native resolution) completes in about 3.7 days, balancing throughput and cost.
Open-Source Resources
We open-source LLaVA-OneVision-1.5 to facilitate future development of LMMs in the community
from transformers import AutoTokenizer, AutoProcessor, AutoModelForCausalLM
from qwen_vl_utils import process_vision_info
model_path = "lmms-lab/LLaVA-One-Vision-1.5-8B-Instruct"
# default: Load the model on the available device(s)
model = AutoModelForCausalLM.from_pretrained(
model_path, torch_dtype="auto", device_map="auto", trust_remote_code=True
)
# default processor
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(inputs, max_new_tokens=1024)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
# pip install git+https://github.com/EvolvingLMMs-Lab/lmms-eval.git
accelerate launch --num_processes=8 --main_process_port 12399 -m lmms_eval \
--model=llava_onevision1_5 \
--model_args=pretrained=lmms-lab/LLaVA-OneVision-1.5-8B-Instruct,attn_implementation=flash_attention_2,max_pixels=3240000 \
--tasks=mmmu_val,mmmu_pro_standard,mmbench_en_test,mmerealworld,mmerealworld_cn,ai2d,ai2d_no_mask,vstar_bench,chartqa,charxiv,docvqa_test,mathvista_testmini,mmstar,scienceqa \
--batch_size=1